
Kafka i OpenEdge cz. I
O integracji OpenEdge z Apache Kafka chciałem napisać od dawna. Najpierw musiałem pokonać pewne kłopoty techniczne, tak aby pokazać pełna ścieżkę od instalacji tejże Kafki do napisania programów w ABL do wysyłania i pobierania danych, ale po kolei. Co to jest Kafka.
Na głównej stronie Apache Kafki możemy przeczytać w tłumaczeniu:
Apache Kafka to rozproszona platforma do strumieniowego przesyłania komunikatów typu open-source, z której korzystają tysiące firm w celu zapewnienia wydajnego przetwarzania danych, analizy przesyłania strumieniowego, integracji danych i aplikacji o znaczeniu krytycznym.
Komunikaty w Kafce pogrupowane są w tzw. topiki (tematy, ang. topic). Nadawca (producer), jak i odbiorca (consumer) powiązani są z jednym lub wieloma topikami.
Rzućmy okiem na uproszczony schemat systemu Kafki.
Kafka zapewnia przesyłanie danych w czasie zbliżonym do rzeczywistego ze źródeł, takich jak bazy danych, aplikacje, czujniki, urządzenia mobilne, usługi w chmurze itd.
Nadawcy i odbiorcy mogą być procesami napisanymi w różnych językach programowania, na różnych systemach operacyjnych; musi istnieć tylko mechanizm aby wpięli się do systemu. Dla klientów ABL również jest taki mechanizm ale o tym napiszę później.
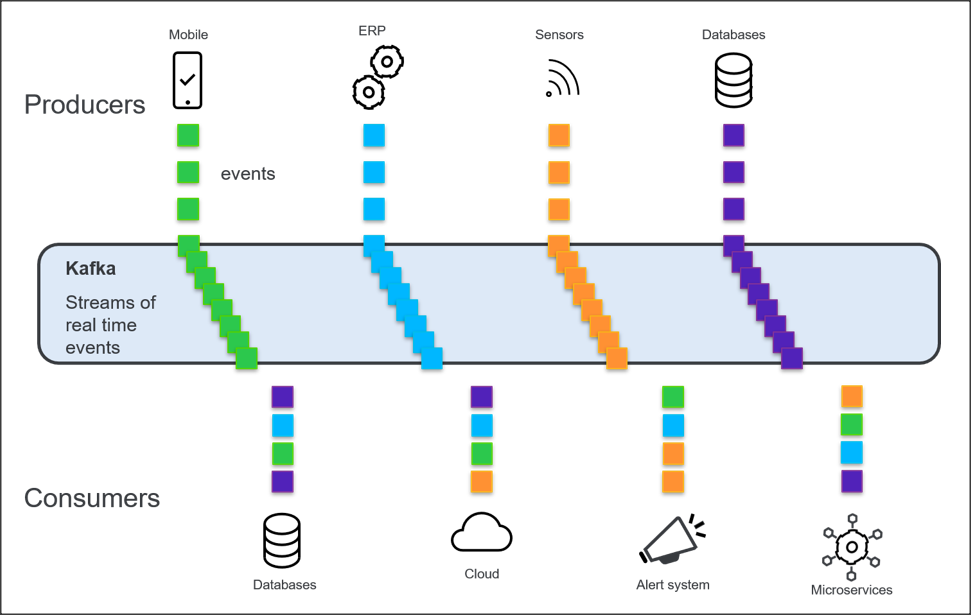
Klientom Progressa ta architektura może przypominać produkty z grupy Sonic, jednakże Kafka jest technologią nieporównywalnie popularniejszą, stosowaną przez wiele wielkich i rozpoznawalnych firm jak Netflix, Twitter, Spotify, Cisco, LinkedIn i dziesiątki innych. Zresztą różnic jest więcej. Kafka jest platformą o wysokiej wydajności i skalowalności, przesyłane komunikaty nie są automatycznie kasowane z kolejki po odczytaniu (mogą być przechowywane bez ograniczenia czasowego) itd…
Komunikaty (nazywane także zdarzeniami lub rekordami) z danego topiku dopisywane są na końcu tzw. partycji. Partycja to uporządkowany rejestr komunikatów, mówiąc niskopoziomowo, jest to plik na dysku brokera, do którego zapisywane są komunikaty. Aby konsument był w stanie odebrać określony komunikat / sekwencję komunikatów – musi znać pozycję ostatnio przeczytanego komunikatu.
OpenEdge udostępnia nowe OpenEdge.Messaging API do wysyłania wiadomości do klastra Kafki poprzez Kafka producer i odbierania wiadomości z tego klastra przez Kafka consumer.
Tyle wstępnych informacji. Chcę Wam pokazać cały proces od zainstalowania Kafki na lokalnej maszynie aby każdy mógł przetestować ten system.
Kafka jest przeznaczona do uruchamiania w systemie Linux i Mac i nie jest przeznaczona do natywnego uruchamiania w systemie Windows. Dlatego w przypadku tej platformy zaleca się stosować technologię Docker lub WSL2.
WSL2 (Windows Subsystem for Linux 2) zapewnia środowisko Linux dla komputera z systemem Windows 10+, które nie wymaga maszyny wirtualnej.
Moja konfiguracja wygląda następująco: Windows 10, zainstalowany WSL2 oraz Windows Terminal, w którym mam dostęp do Linuxa Ubuntu.
Instaluję Apache Kafka korzystając z oryginalnej strony. Polega to (ach ten Linux!) jedynie na pobraniu i rozpakowaniu plików. Najpierw niezbędne jest zainstalowanie infrastruktury do utrzymywania i koordynowania brokerów. Może to być KRaft lub ZooKeeper. Ja wybieram to drugie rozwiązanie.
W Windows Terminal otwieram kilka zakładek dla Ubuntu.
W pierwszej uruchamiam ZooKeepera:
sudo bin/zookeeper-server-start.sh config/zookeeper.propertiesW drugiej Kafkę:
sudo bin/kafka-server-start.sh config/server.propertiesJak widać cała operacja jest bardzo prosta. Mogę dalej podążać za instrukcją: dodać topik, okno consumera, nadawać i odbierać komunikaty. Ta testowa konfiguracja odwołuje się do parametru bootstrap-server, który zawiera listę par „hostname:port”, które adresują jednego lub więcej brokerów. W tym prostym przypadku dodanie topicu wygląda następująco:
kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092Zastopujmy teraz wszystkie procesy Kafki poprzez zamknięcie zakładek.
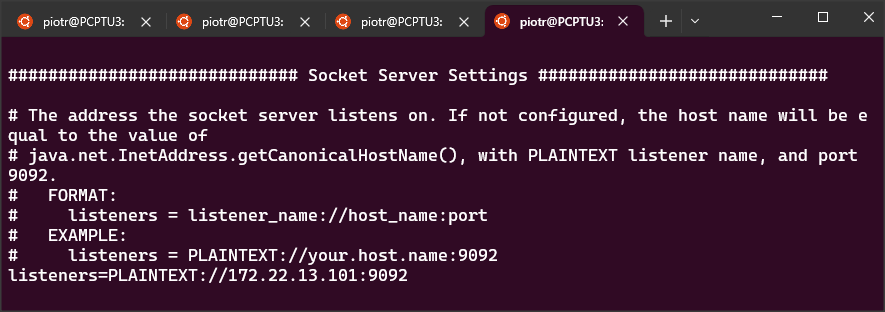
Ponieważ będę potrzebował mieć dostęp z zewnętrznej aplikacji ABL, więc zamiast wartości localhost muszę wstawić wartość ip “maszyny” z Linuxem. Jeśli ip wynosi np. 172.22.13.101, to tę wartość wstawiam w następujących miejscach.
plik: config/server.properties
listeners=PLAINTEXT://172.22.13.101:9092
jak poniżej:
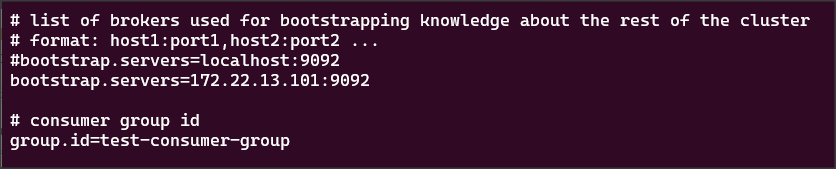
plik: config/producer.properties
bootstrap-servers=172.22.13.101:9092

plik: config/consumer.properties
bootstrap-servers=172.22.13.101:9092
OK, uruchamiam ponownie procesy ZooKeepera i Kafki. W trzeciej zakładce dodaję topic mytopic,
bin/kafka-topics.sh --create --topic mytopic --bootstrap-server 172.22.13.101:9092a następnie uruchamiam proces producera:
bin/kafka-console-producer.sh --topic mytopic --bootstrap-server 172.22.13.101:9092a w oknie czwartym consumera:
bin/kafka-console-consumer.sh --topic mytopic --bootstrap-server 172.22.13.101:9092Wysyłam przykładowe wiadomości w oknie producera.
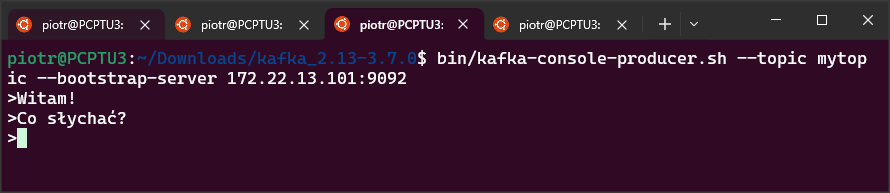
Pojawiają się one natychmiast w oknie consumera.
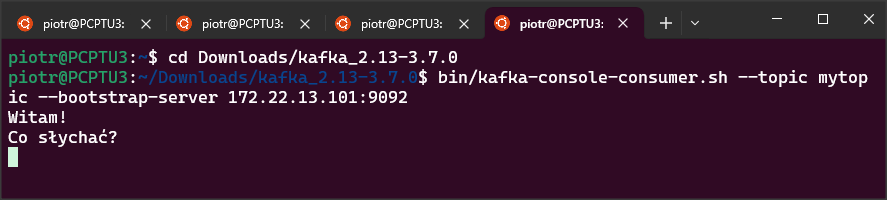
OK, mamy zatem skonfigurowany prosty system Kafki i w następnym wpisie pokażę jak przyłączyć się do niego z poziomu aplikacji ABL.