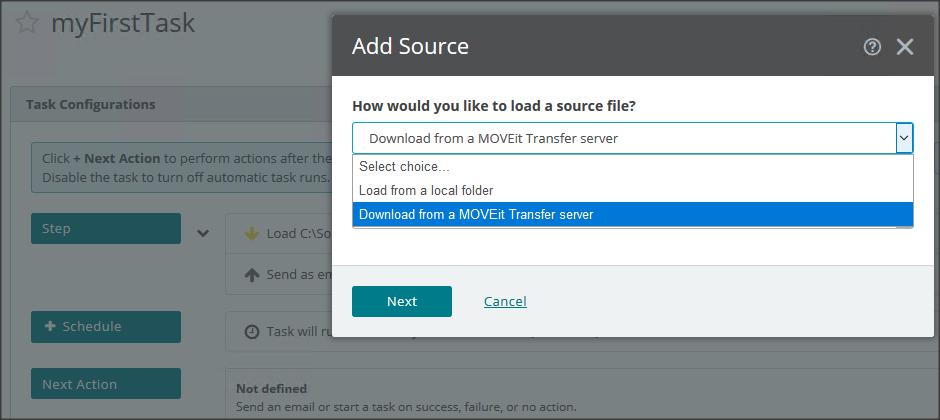
Nareszcie mamy na rynku następną wersję LTS (Long-Term Support) OE 12.8. Poprzednia OE 12.2 pojawiła się 4 lata temu. 12.8 zawiera elementy wprowadzane w kolejnych wersjach Innovation 12.3-12.7 włącznie, co z grubsza opisałem na tym blogu. Teraz zobaczymy co ciekawego jest w samej wersji 12.8.
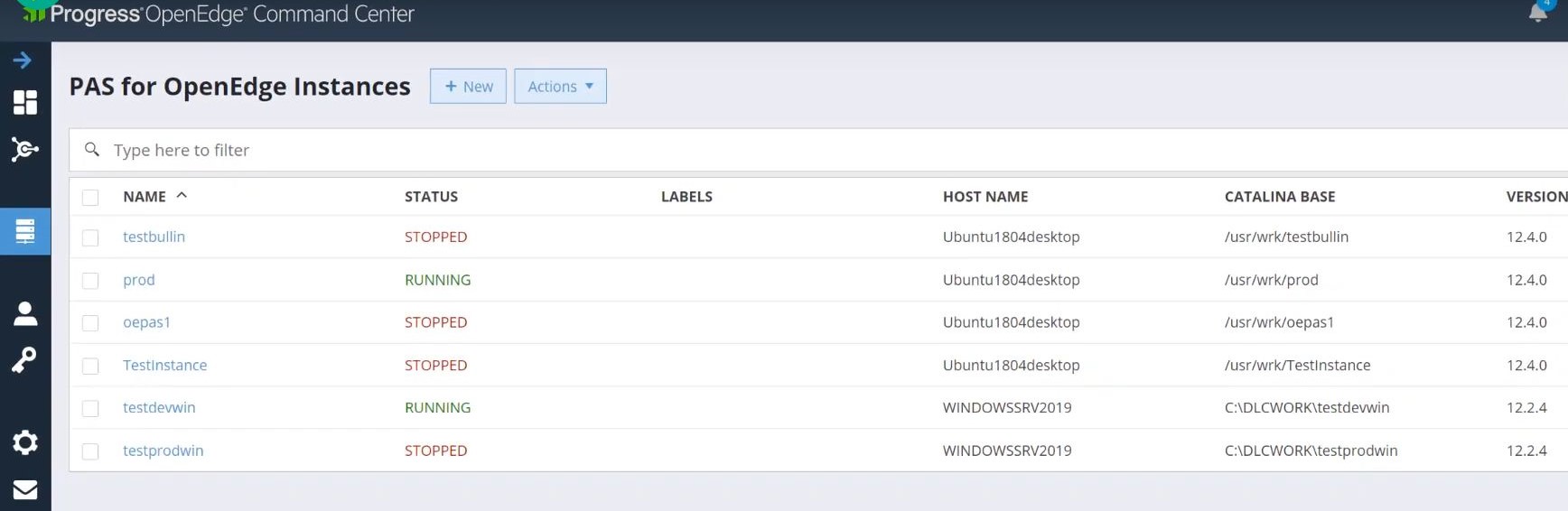
Zacznijmy od administracji PASOE. W poprzednim artykule opisałem nową komendę OEMANAGER, stosowaną do przeglądu statystyk i podstawowych operacji. Osoby zainteresowane odsyłam bezpośrednio do tego wpisu.
Inną ciekawą i bardzo ważną funkcją jest zapowiadana technologia Dynamic Data Masking (DDM) służąca do dynamicznego zaciemniania lub maskowania wrażliwych danych w bazie przed nieautoryzowanymi użytkownikami. Przykładem może być maskowanie w danych osobowych pola “pesel” lub w danych finansowych pola “wynagrodzenie”.
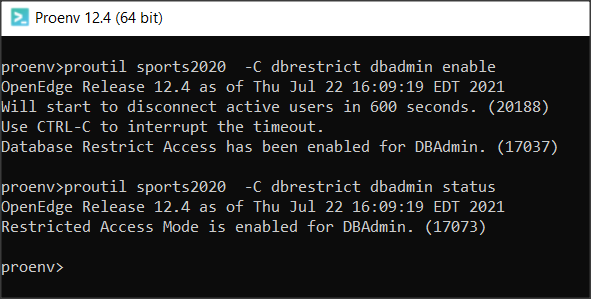
Technologia ta składa się niejako z dwóch etapów. Pierwszy należy do administratora bazy i polega na włączeniu funkcji poleceniem PROUTIL [baza] -C ENABLEDDM. Komenda ta sprawdza czy baza jest licencjonowana do użycia DDM. Następne polecenie PROUTIL [baza] -C ACTIVATEDDM uaktywnia DDM w bazie (dostępne są także opcje DEACTIVATEDDM i DISABLEDDM).
DDM do kontrolowania uprawnień przyznawanych użytkownikom w zakresie maskowania danych wykorzystuje konfigurację opartą na rolach. Administrator DDM może skonfigurować maskę nad polami tabeli, która ukrywa wrażliwe dane w zestawie wynikowym zapytania, a także utworzyć i przypisać nowe tagi autoryzacyjne do ról zdefiniowanych przez użytkownika.
Drugim etapem jest zatem zdefiniowanie własnych ról oraz znaczników autoryzacji i przypisanie ich do zdefiniowanych ról, przydzieleniu ról uwierzytelnionym użytkownikom, konfiguracja masek i znaczników autoryzacji dla pól tabeli. Etap ten realizujemy wykorzystując interfejs IDataAdminService, który udostępnia zestaw właściwości i metod obsługujących operacje CRUD związane z DDM. Poniżej zamieszczam wzięty z dokumentacji przykład utworzenia własnej roli TestUser.
USING OpenEdge.DataAdmin.*.
VAR DataAdminService oDAS. VAR IRole oRole.
VAR LOGICAL lResult.
ASSIGN oDAS = NEW DataAdminService(LDBNAME("DICTDB")).
oRole = oDAS:NewRole("TestUser").
oRole:Description = "A Test User".
// This role will be used for DDM
oRole:IsDDM = true.
lResult = oDAS:CreateRole(oRole).
DELETE OBJECT oDAS.
W OpenEdge jest systematycznie rozwijana technologia wizualizacji danych poprzez standard OpenTelemetry i wykorzystanie zewnętrznych aplikacji typu APM (Application Performance Monitoring).
W 12.8 dodano możliwość monitorowania procesów agentów PASOE oraz klientów ABL. W tym drugim przypadku należy uruchomić sesję ABL z parametrem -otelconfig myotelConfig.json, wskazującym na plik konfiguracyjny w standardzie JSON. Przykładowy taki plik zamieszczam poniżej:
{
"OpenTelemetryConfiguration": {
"exporters": {
"otlp": {
"grpc": [
{
"endpoint": "http://localhost:4317",
"span_processor": "batch",
}
]
}
}
},
"OpenEdgeTelemetryConfiguration": {
"trace_procedures": "Customer*.p",
"trace_classes": "*",
"trace_abl_transactions": true,
"trace_requires_parent": true,
"trace_request_start": true
}
}
Plik ten określa m.in. proces OTel Collectora (port:4317), a także maskę monitorowanych plików np. każda procedura zawierająca w nazwie słowo Customer i wszystkie klasy (*). O pełnej konfiguracji monitorowania przy pomocy Open Telemetry napiszę innym razem.
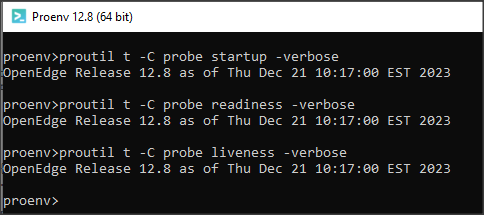
A teraz kilka słów na temat administrowania bazą. Pojawiła się komenda PROUTIL [baza] -C PROBE [state] która sprawdza aktualny operacyjny stan bazy. Sprawdzane są trzy stany (parametr state):
- startup – czy baza danych zakończyła uruchamianie
- liveness – czy broker bazy danych działa i odpowiada
- readiness – czy baza danych może wykonywać operacje (np. CRUD)
Jeśli wykonanie komendy z parametrem –verbose nie wyświetli żadnych informacji, będzie to oznaczać sukces.
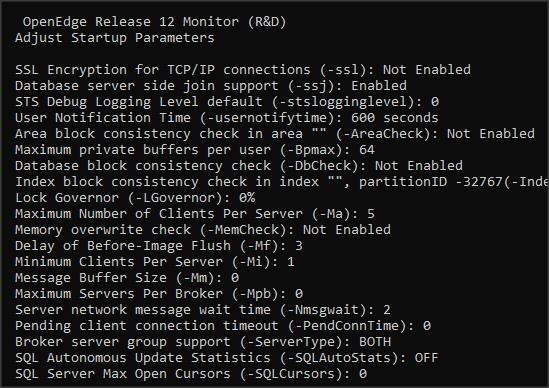
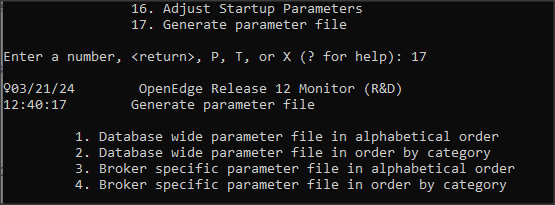
Administratorzy wykorzystujący możliwość zwiększania wartości niektórych parametrów poleceniem PROUTIL… INCREASETO mogą teraz wygenerować plik .pf z aktualnymi ustawieniami podczas runtime’u. Daje to możliwość zapamiętywania i porównywania różnych konfiguracji. Plik możemy wygenerować wykorzystując tablice VST lub z poziomu narzędzia PROMON -> R&D Advanced Options -> 4. Administrative Functions -> 17. Generate parameter file
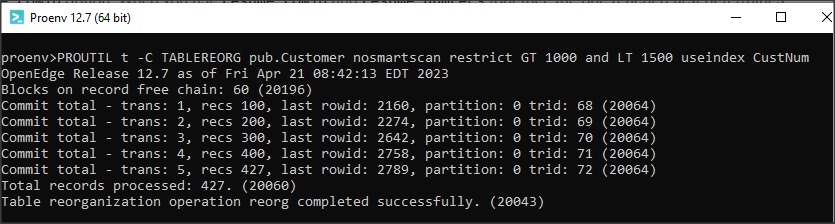
Dużym zainteresowaniem cieszyła się nowa komenda PROUTIL… TABLEREORG wprowadzona w OE 12.7, która pozwala na przeładowanie tablicy i polepszenie stopnia fragmentacji i rozrzucenia rekordów przy pracującej bazie. Podczas ładowania wykorzystuje się sortowanie rekordów wg indeksu. W OE 12.7 musiał to być indeks unikalny, jednakże czasami lepszą wydajność można uzyskać dla indeksu nieunikalnego ale często używanego w aplikacji. W OE 12.8 indeksy mogą już być nieunikalne.
Inne ciekawe i ważne nowości to np. podniesie wersji Spring Security 6.1.4 oraz Tomcata 10.1.15. Ma to swoje implikacje podczas migracji z wcześniejszych wersji PASOE.
W Developer’s Studio dodano typ projektu .NET z narzędziami: Class Browser, Content Assist, Outline View, co ma pomóc w programowaniu przy użyciu .NET 6.
Jest jeszcze sporo innych nowinek po które zapraszam do dokumentacji.