Partycje Tabel OpenEdge cz. I
W ostatnim czasie kilka osób prosiło mnie o wyjaśnienie na czym polega partycjonowanie tabel w bazach OpenEdge. Ten temat czasem powraca w rozmowach z Wami, więc postanowiłem go nieco przybliżyć.
Partycjonowanie tabel (Table Partitioning) to oddzielny produkt dla baz Enterprise, umożliwiający dzielenie dużych tabel na mniejsze części pod względem logicznym zwane partycjami.
Partycje są zaimplementowane na poziomie bazy danych i przezroczyste dla aplikacji. Korzystanie z partycjonowanych tabel może wymagać niewielkich zmian w kodzie aplikacji lub nie wymagać ich wcale.
Uwaga: obiekty podzielone na partycje muszą znajdować się w storage area Typ II.
Partycjonowanie posiada kilka istotnych cech. Partycje w tabeli są niezależne, więc można realizować do nich jednoczesny dostęp, poprawiając wydajność zapytań. Jeśli jedna partycja w tabeli nie jest dostępna, pozostałe partycje są nadal dostępne dla aplikacji.
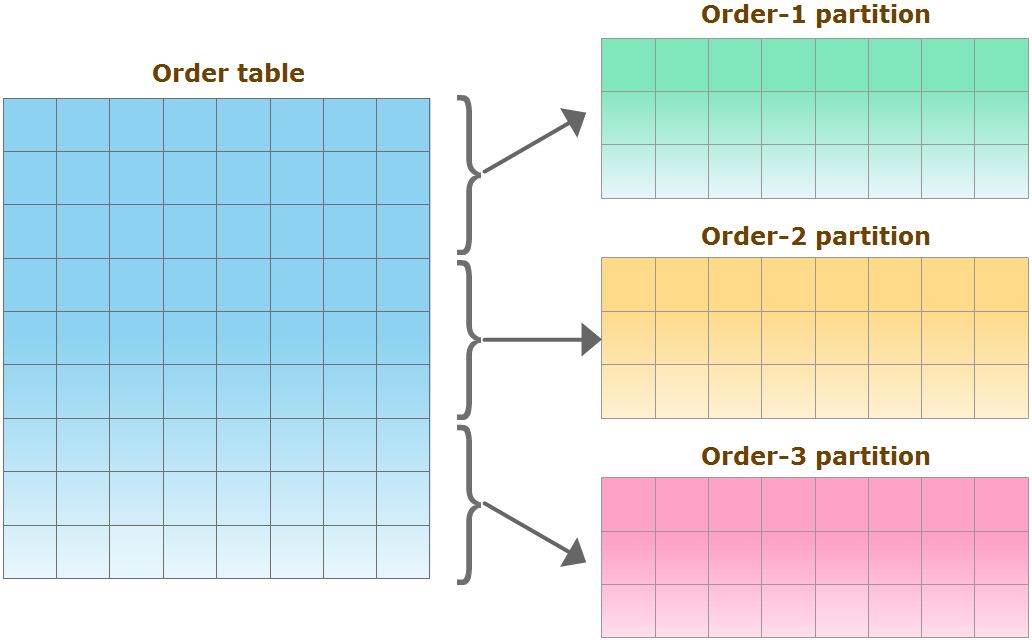
Każdy rekord tabeli podzielonej na partycje ma te same kolumny.
Każdy rekord może znajdować się tylko w jednej partycji.
Każda partycja może znajdować się we własnym obszarze przechowywania (storage area),
Każda partycja może być niezależnie modyfikowana i zarządzana bez wpływu na inne partycje tej samej tabeli.
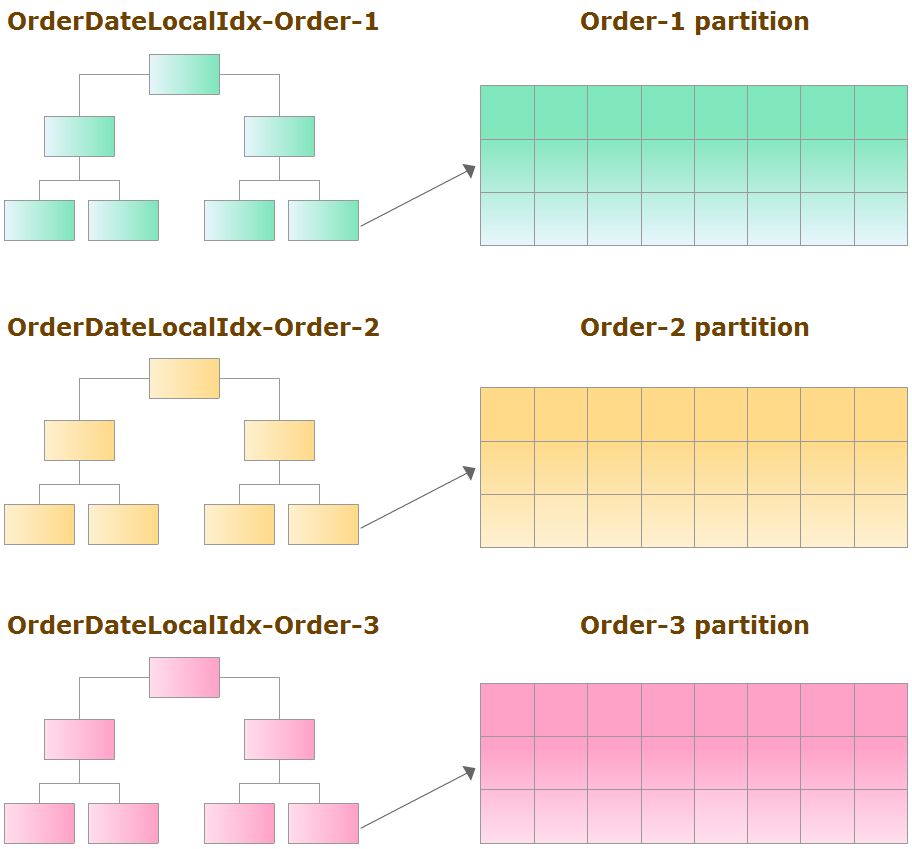
Ponadto:
indeksy związane z tabelami podzielonymi na partycje można również podzielić na partycje (tzw. lokalne indeksy).
Podobnie jak partycje tabel, każdy lokalny indeks może znajdować się we własnym obszarze przechowywania i być niezależnie zarządzany. Oprócz indeksów lokalnych mogą istnieć także indeksy globalne dla wszystkich danych w tabeli, bez względu na wydzielone partycje.
Kiedy warto stosować tę technologię?
Np. dla tabel zawierających dane historyczne, które muszą być
archiwizowane. Ciekawą cechą partycji jest to, że jeśli jakaś partycja zawiera dane, które nie mogą być modyfikowane, może być ustawiona tylko do odczytu. W ten sposób w tabeli można modyfikować tylko dane aktualne, a nie zarchiwizowane.
Inne przykładowe przyczyny:
Tabele zawierające dane, które muszą być rozłożone na różnych urządzeniach pamięci masowej.
Duże tabele, które muszą podlegać okresowym operacjom na rekordach i indeksach.
Tabele zawierają kolumny, wg których można logicznie pogrupować dane.
Tabele zawierające dane z częstymi zapytaniami z frazą TABLE-SCAN, a nie WHOLE-INDEX.
Tabele, które będą rosły do bardzo dużych rozmiarów.
Partycjonowanie wykorzystuje jedną kolumnę (tzw. partition key) do jednoznacznej identyfikacji każdej partycji. Podział może być według zakresu (np. zakres dat) lub według listy (lista odrębnych wartości kolumn, np. kraje, województwa, itp.). Kolumna partition key nie może mieć wartości nieokreślonych (“?”).
Należy dodać, że dane w partycji można podzielić na dalsze partycje (możliwe jest 15 poziomów podziału). Np. dzielimy zamówienia (tablica order) według zakresu dat, a następnie każdą partycję dzielimy dodatkowo na subpartycje wg kraju.
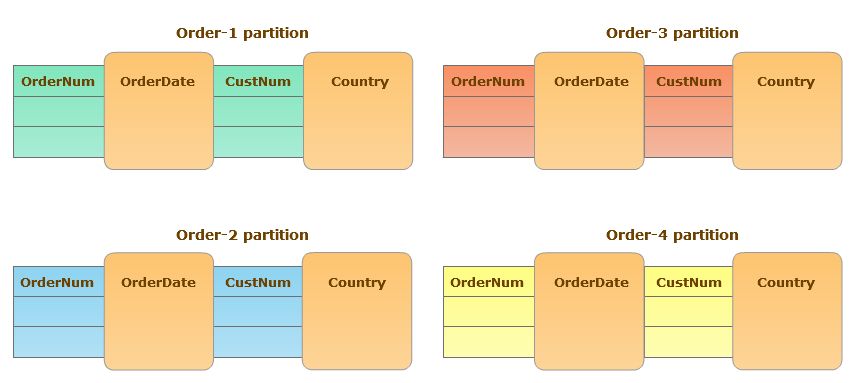
Sposób w jaki tabele są podzielone jest opisane w tzw. zasadach partycjonowania (partition policy), znajdujących się w meta-schemacie bazy.
W następnym odcinku pokażę jak w praktyczny sposób stworzyć partycje i przenieść do nich dane.