Bezpieczeństwo w PASOE cz. V – OE Realm
Po ostatnim artykule dostałem pytanie: czy można wykorzystać obiekt CLIENT-PRINCIPAL w PASOE bez konieczności korzystanie z LDAP. Otóż można i zaraz pokażę jak to zrobić na podstawie informacji zaczerpniętych z bazy wiedzy (000194706). (Uwaga: technika ta dotyczy wersji OE 12.2. W bazie można znaleźć podobne rozwiązanie np. dla OE 11, które nie działa poprawnie).
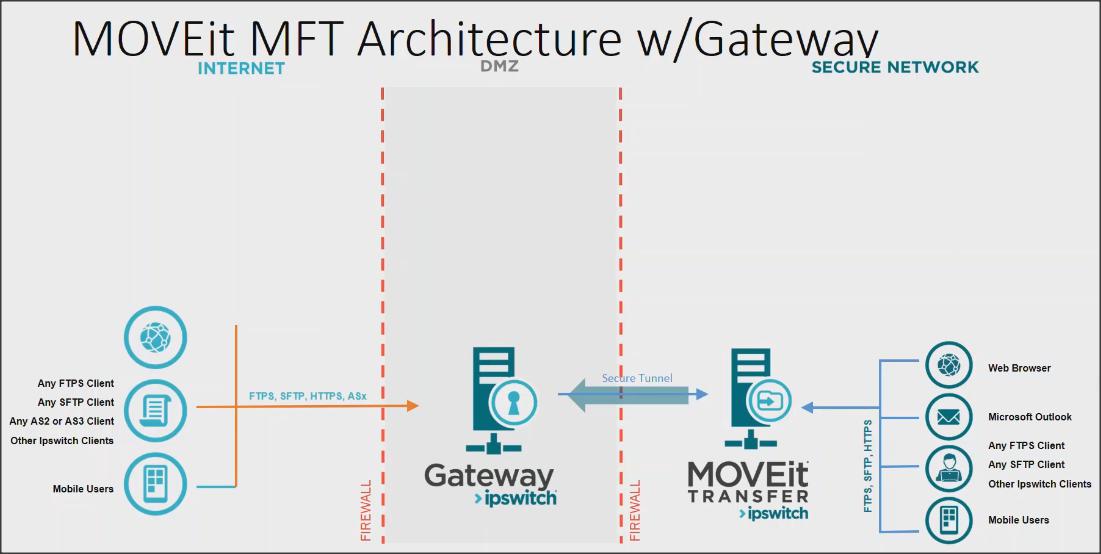
Na początek trzeba powiedzieć czym jest OERealm. Jest to implementacja SPA (Single Point of Authentication), rozszerzająca proces uwierzytelniania Spring Security. Implementacja ta składa się z komponentu klienta i servera OERealm napisanych w języku obiektowym ABL (OO ABL).
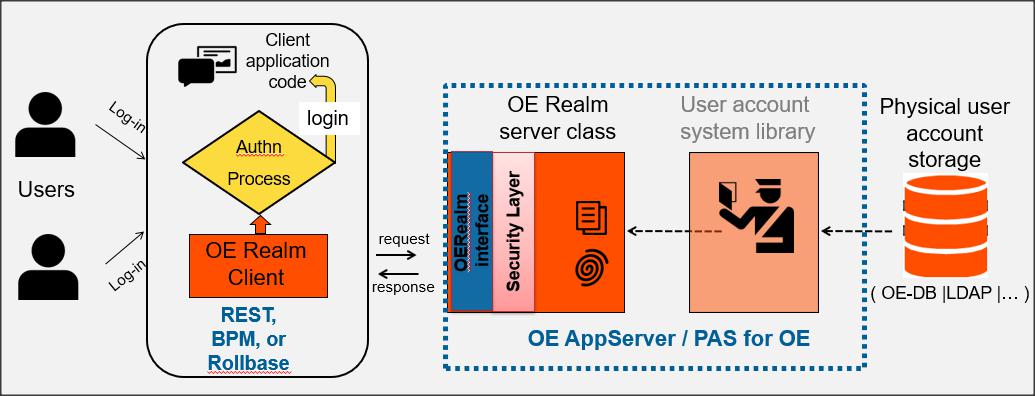
Źródłem danych może być nie tylko baza, ale także omawiane wcześniej LDAP lub inne żródło.
OE Realm Service Interface jest klasą OO ABL, która zawiera metody sprawdzające tożsamość użytkownika i dostarczające informację o atrybutach zweryfikowanego użytkownika.
Po stronie klienta należy zaimplementować własny proces uwierzytelniający. Aktualnie klientem OE Realm może być REST, BPM i Rollbase.
W niniejszym artykule zajmiemy się uwierzytelnianie klientów REST, przy czym dane użytkowników są zdefiniowane w tabeli _User w domenach bazy danych OpenEdge.
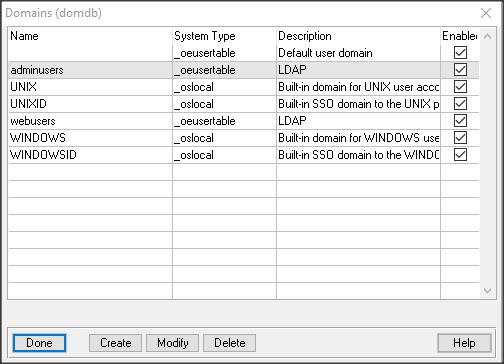
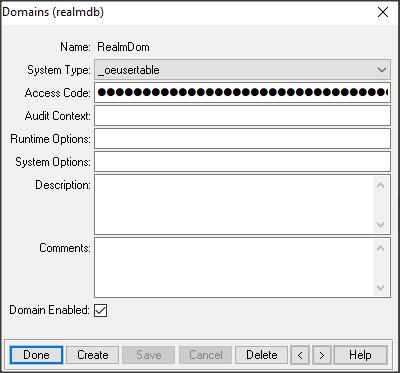
Na początek przygotujmy bazę (realmdb, kopia bazy sports2000), dadajmy domenę RealmDom, kod dostępu do domeny realmpa.
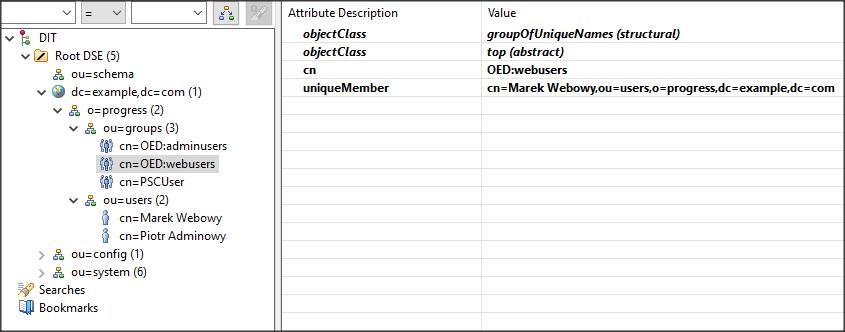
Dodajmy użytkownika restuser1 do domeny RealmDom oraz user1 do domeny pustej (hasło np. takie samo jak nazwa użytkownika).
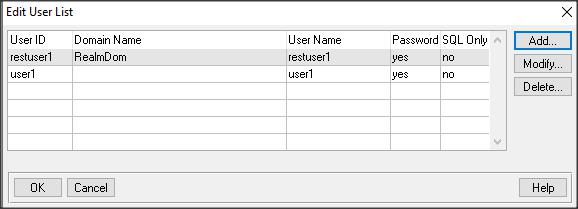
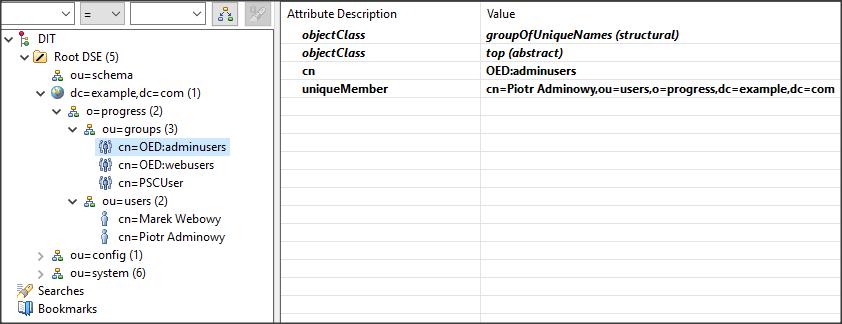
Teraz trzeba stworzyć rolę i nadać ją użytkownikowi restuser1…
CREATE _Sec-role. ASSIGN _Role-name = “PSCUser” _Role-description = “User level role”. _Role-creator = “”. /* Name of the user or Role that created this role */ CREATE _sec-granted-role. ASSIGN _sec-granted-role._grantee = “restuser1@RealmDom”. _sec-granted-role._role-name = “PSCUser”. _sec-granted-role._grantor = “”. /* the user or role that granted use of this role */ _sec-granted-role._grant-rights = YES. _sec-granted-role._granted-role-guid = substring(base64-encode(generate-uuid), 1, 22).
…oraz sekwencję wymaganą przez klasę OEUserRealm.cls.
USING OpenEdge.DataAdmin.*.
DEFINE VARIABLE sequence AS ISequence NO-UNDO.
DEFINE VARIABLE service AS CLASS DataAdminService.
service = NEW DataAdminService().
sequence = service:NewSequence("Next-User-Num").
sequence:InitialValue = 1.
sequence:IncrementValue = 1.
sequence:IsCyclic = FALSE.
sequence:MaximumValue = ?.
service:CreateSequence(sequence).
Tworzymy nową instancję PASOE (nazwałem ją realmpas) z przyłączoną bazą realmdb.
Aby tylko ta instancja mogła uruchomić plik klasy Oe Realm, wygenerujemy plik CP poleceniem:
genspacp -user oerealm -password RESTSPAPassword -role RESTSpaClient -file realm.cp
W komendzie tej dane użytkownika nie mają nic wspólnego z użytkownikami zdefiniowanymi w bazie.
Dane te będą znajdować się w pliku spaservice.properties, który należy umieścić w podkatalogu …/realmpas/openedge.
Wygenerowany plik realm.cp umieścimy natomiast w podkatalogu …/realmpas/common/lib/.
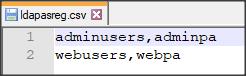
Teraz, podobnie jak w poprzednim artykule, wygenerujemy zaszyfrowany plik rejestru. Najpierw tworzymy prosty plik tekstowy domreg.csv zawierający tylko jedną linię: nazwa domeny, kod dostępu.
RealmDom, realmpa.
Zaszyfrowany plik generujemy poleceniem gendomreg domreg.csv ABLDomainRegistry.keystore.
Nazwa pliku jest dowolna. W tym przykładzie jest to nazwa domyślna, używana w pliku z ustawieniami PASOE. Umieszczamy go w podkatalogu …/realmpas/conf.
Plik OEUserRealm.properties kopiujemy do podkatalogu …/realmpas/openedge. Zawiera on tylko dwie linie:
validateCP=true debugMsg=true
Wszystkie pliki potrzebne aby uruchomić ten przykład możemy pobrać STĄD.
Przejdżmy teraz do Developer’s Studio i stwórzmy prosty projekt oparty na naszym PASOE typu REST z wykorzystaniem JSDO (pokazywałem kiedyś jak to zrobić na tym blogu). W projekcie tym (nazwałem go myrealm) tworzymy Busineee Entity dla tabeli Customer. Zresztą, może to być jakikolwiek inny projekt dla serwisu REST. Mamy więc projekt i wygenerowany podkatalog AppServer. Importujemy do tego podkatalogu pobraną strukturę psc/stat/realm z plikami klasy.
Jeśli tworzycie takie projekty to pewnie dobrze wiecie jak to zrobić. Jeśli nie, to wg. mnie, najwygodniej utworzyć plik zip tylko ze strukturą i plikami, które chcemy zaimportować (pobrany plik .zip zawiera także ustawienia, plik .cp itp.), a następnie klikamy prawym klawiszem na podkatalog AppServer i wybieramy import -> Archive File. Radzę skasować pliki .r ponieważ były skompilowane dla bazy sports2000 i mogą generowac błędy.
Przechodzimy teraz do pliku z ustawieniami PASOE oeablSecurity.properties. Możemy to zrobić bezpośrednio w podkatalogu …\realmpas\webapps\myrealm\WEB-INF, bądź z Dev. Studio pod naszym projektem PASOEContent/WEB-INF/oeablSecurity.properties.
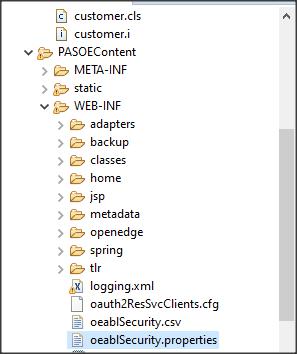
Dodajemy w nim ustawienia lub upewniamy się, że są tam takie jak poniżej (niektóre ustawienia powinny mieć domyślne wartości).
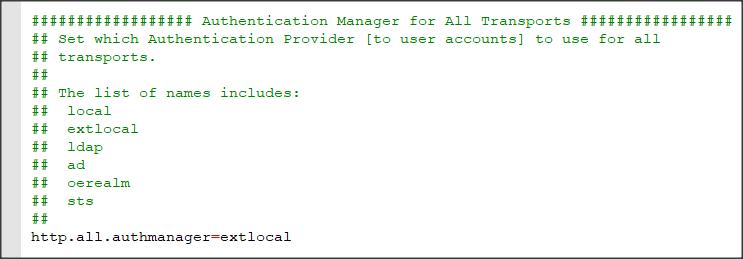
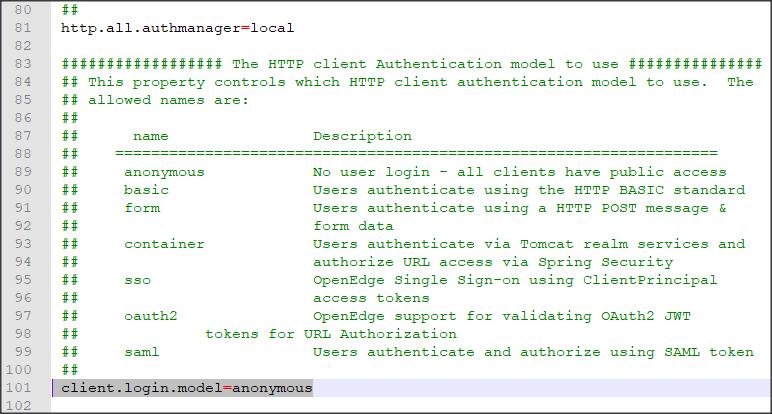
http.all.authmanager=oerealm client.login.model=form OEClientPrincipalFilter.enabled=true OEClientPrincipalFilter.registryFile=ABLDomainRegistry.keystore OERealm.UserDetails.realmClass=psc.stat.realm.OEUserRealm OERealm.UserDetails.grantedAuthorities=ROLE_PSCUser.ROLE_PSCAdmin,ROLE_PSCDebug OERealm.UserDetails.appendRealmError=false OERealm.UserDetails.realmTokenFile=realm.cp
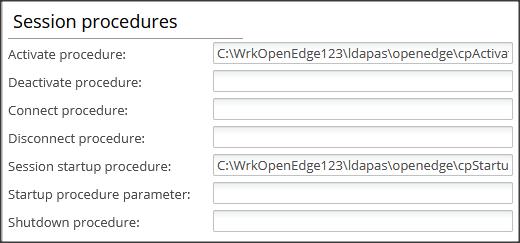
W ustawieniach PASOE dodajemy procedurę activate.p. Można to zrobić w OE Explorer (jak poniżej), w pliku openedge.properties lub w Dev. Studio Open Launch configuration -> Startup. Ta ostatnia metoda ustawia zmienne tylko tymczasowo i jest bardzo wygodna w testowaniu.
Procedura ta jest zapisana w podkatalogu …/realmpas/openedge. Uruchamia ona procedurę dumpCP.p, którą także musimy umieścić w tym katalogu. Zapisuje ona do logu dane o Client-Proncipal.
Po tych wszystkich zabiegach tak wygląda podkatalog …/realmpas/openedge…
… a tak pliki w projekcie.
Uruchamiam PASOE i próbuję zalogować się do mojego serwisu: http://localhost:8853/myrealm/static/auth/login.jsp
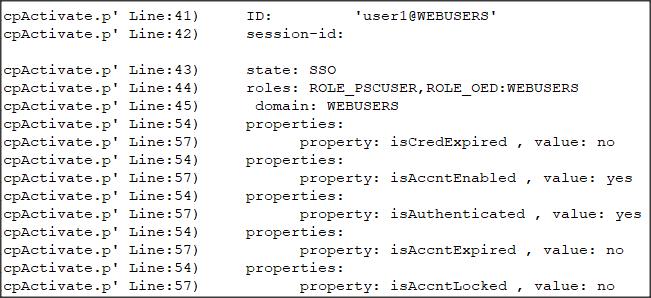
Próba jest udana i w logu agenta możemy znaleźć nast. informacje:
..... (Procedure: 'dumpCP.p' Line:16) psc.stat.realm.OEUserRealm&ValidateUser Client-Principal: (Procedure: 'dumpCP.p' Line:17) ID: 'oerealm@OESPA' (Procedure: 'dumpCP.p' Line:18) session-id: 1ehUo504Taq+XFpP8CFSMw (Procedure: 'dumpCP.p' Line:19) state: SSO (Procedure: 'dumpCP.p' Line:25) details: The CLIENT-PRINCIPAL object credentials were validated by an external system (Procedure: 'dumpCP.p' Line:27) roles: RESTSpaClient ..... (Procedure: 'ValidateUser psc.stat.realm.OEUserRealm' Line:590) Lookup ABL user account for: restuser1@RealmDom (Procedure: 'ValidateUser psc.stat.realm.OEUserRealm' Line:599) ValidateUser found user: restuser1@RealmDom (Procedure: 'ValidateUser psc.stat.realm.OEUserRealm' Line:613) Lookup user account for: restuser1@RealmDom returned id: 2 .....
Pliki klas możemy oczywiście napisać sami, ale potrzebna jest do tego odpowiednia wiedza. Na początek warto bazować na tych przykładowych plikach.
I to by było na tyle.