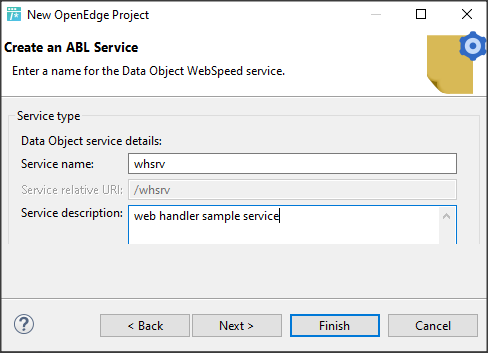
OpenEdge 12.7
5 maja pojawiła się wersja OpenEdge 12.7. Ma być ona ostatnią z wersji Innovation dla dwunastki ponieważ ostatnia, zapowiadana na koniec roku, ma być wersją LTS. Przyjrzyjmy się wybranym nowościom.
PROSTRCT REMOVEONLINE – nowa komanda poprawiająca dostępność bazy danych. Umożliwia usuwanie extentów lub całych obszarów bez konieczności zamykania bazy.
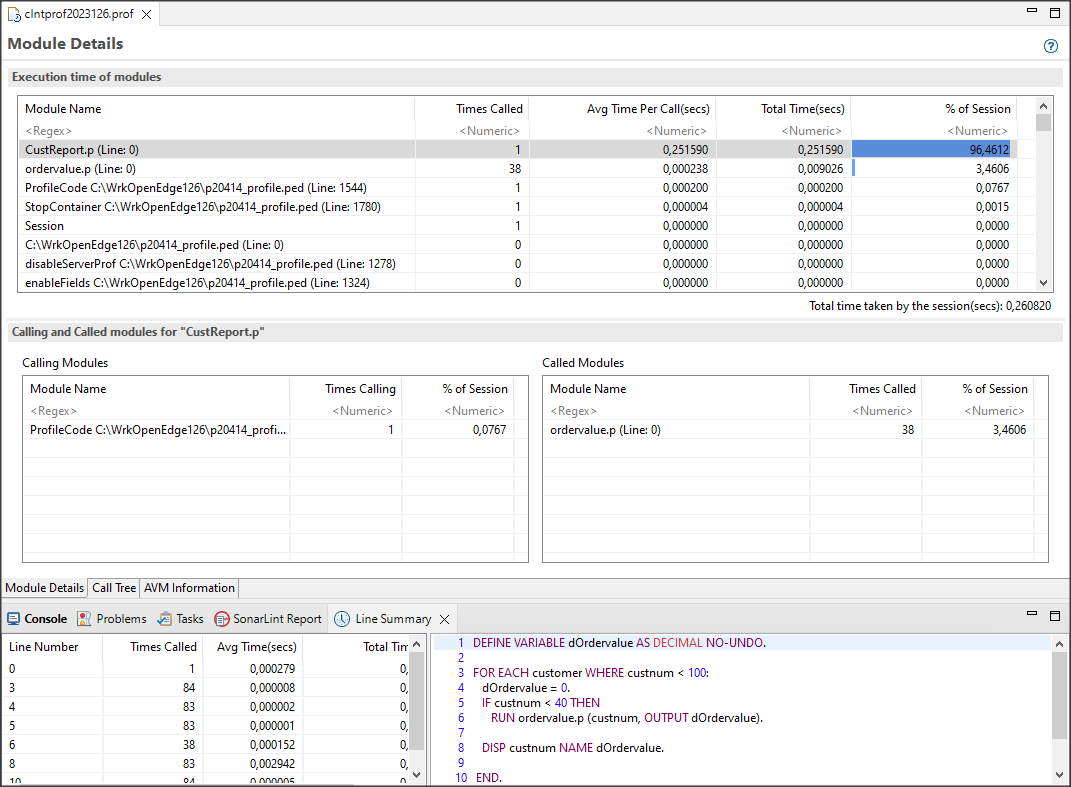
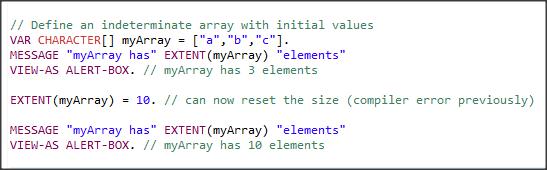
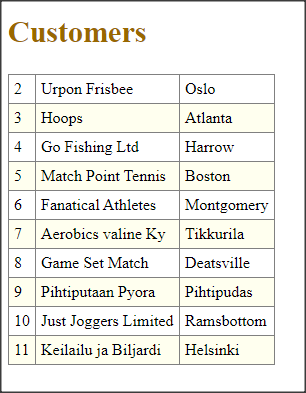
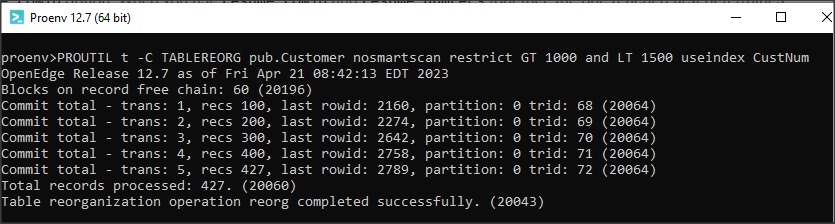
PROUTIL TABLEREORG to narzędzie służące do poprawy stopnia fragmentacji w tabelach (zastępuje operacje dump i load online) dla obszarów typu II. Wprowadzono je w OE 12.3, a teraz dodano nowe parametry np. restrict czy nosmartscan. Pierwsza opcja jest przeznaczona dla dużych tabel i pozwala na reorganizację wybranego fragmentu tabeli wg. wartości pola. Druga opcja wyłącza domyślne inteligentne skanowanie. Przykład poniżej.
Wprowadzono nowy typ pakietu (lub biblioteki) kodu aplikacji ABL, który można podpisać i weryfikować, aby mieć pewność, że skompilowany kod aplikacji ABL nie został uszkodzony ani zmodyfikowany. Ten nowy typ biblioteki jest znany jako plik archiwum i ma rozszerzenie .apl. Do utworzenia archiwum, dodawania r-kodów służy komenda PROPACK, a do podpisywania PROSIGN.
OpenEdge obsługuje teraz OAuth2 i SAML do uwierzytelniania i autoryzacji. Te standardowe protokoły zapewniają bezpieczny i wygodny mechanizm uwierzytelniania użytkowników bez udostępniania poufnych informacji. OpenEdge Authentication Gateway może automatycznie przekonwertować zweryfikowane tokeny na token OpenEdge Client Principal, który możemy obsługiwać w aplikacjach ABL.
Administrowanie PASOE: do tej pory można było skonfigurować instancje tak aby w razie potrzeby agent wielosesyjny uruchamiał dodatkowe sesje, ale nie było możliwości aby te sesje były automatycznie przycinane. W obecnej wersji OpenEdge dodano nowe właściwości do pliku openedge.properties, które umożliwiają administratorowi systemu skonfigurowanie instancji PASOE tak, aby sesje ABL były przycinane gdy nie są już potrzebne czy też gdy osiągnęły limit czasu lub pamięci.
W Developer Studio dodano ABL Type Hierarchy View, który pokazuje relacje rodzic-dziecko między klasami ABL i interfejsami, aby pomóc programiście ABL zobaczyć hierarchię i strukturę dziedziczenia klasy i przechodzenie do dowolnego elementu widocznego w widoku.
Dla wykorzystujących AI Archiver do zapisu After Image pojawiła się ciekawa możliwość wystartowania tego procesu online bez konieczności wykonania backupu. Jest to szczególnie istotne dla dużych baz gdy wykonanie kopii powodowało wstrzymanie wykonywanie transakcji.
W operacja przywracanie bazy PROREST dodano parametry do wykonania jej jako proces wielowątkowy.
Jest jeszcze kilka nowinek po które odsyłam do dokumentacji.