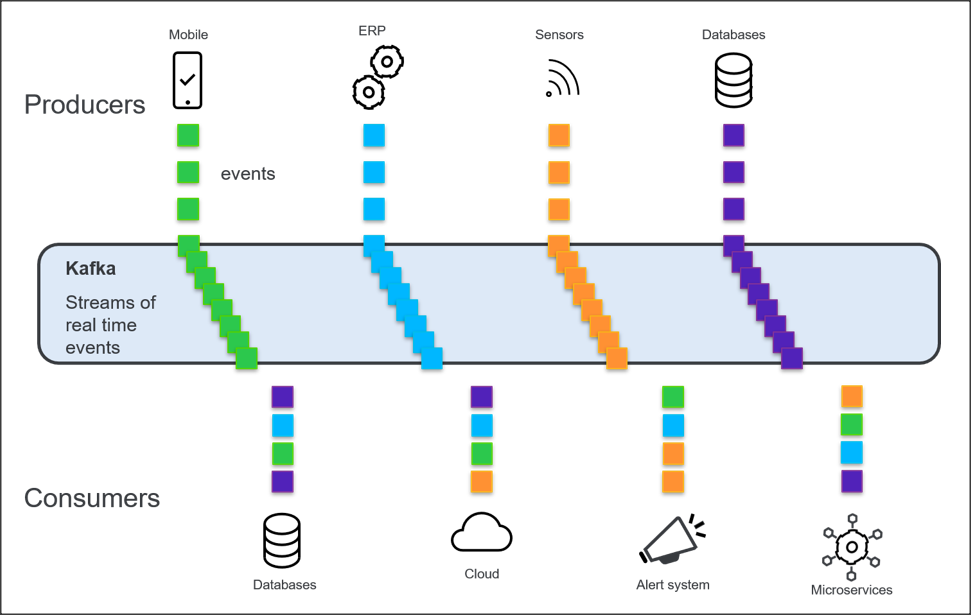
Kafka i OpenEdge cz. II
W poprzednim artykule pokazałem jak zainstalować i skonfigurować lokalne środowisko Kafki a teraz pokażę jak zintegrować je z OpenEdgem.
Niektórzy z Was, którzy będą potrzebować zintegrować się z istniejącą architekturą Kafki, będą zainteresowani od tego właśnie miejsca.
Najlepiej w tym celu sprawdzić dokumentację OE dla danej wersji np. online. Ważne, że trzeba posiadać wersję OE 12.5 lub wyższą.
Pierwszym krokiem jest pobranie biblioteki Apache Kafka C/C++ dla Windows lub Unixa (link Download package po prawej stronie). Minimalna wymagana wersja to 1.7, ale zaleca się pobranie ostatniej wersji.
Gdy plik mamy już pobrany zmieniamy jego rozszerzenie z nupkg na zip i rozpakowujemy. W przypadku Windows będą nas interesowały pliki z podkatalogu runtimes\win-x64\native\, które umieszczamy w katalogu roboczym naszej aplikacji ABL.
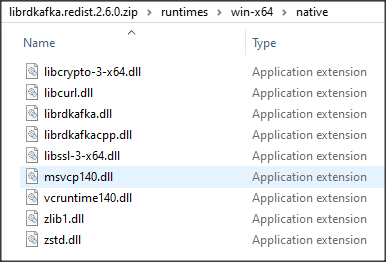
Dodajemy do PROPATH następujace biblioteki:
- $DLC/tty/netlib/OpenEdge.Net.pl
- $DLC/tty/messaging/OpenEdge.Messaging.pl
Teraz możemy wziąć się za napisanie procedury w ABL, a raczej za pobranie jej z dokumentacji i małą kastomizację.
/* producer.p */
using OpenEdge.Messaging.*.
using OpenEdge.Messaging.Kafka.*.
block-level on error undo, throw.
var RecordBuilder recordBuilder.
var KafkaProducerBuilder pb.
var IProducer producer.
var IProducerRecord record.
var ISendResponse response.
pb = cast(ProducerBuilder:Create("progress-kafka"), KafkaProducerBuilder).
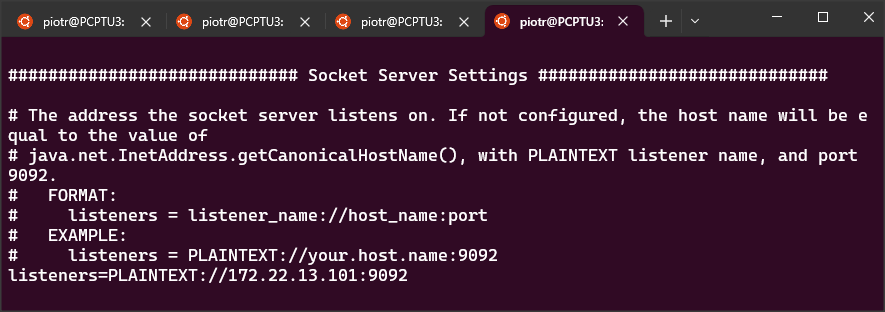
pb:SetBootstrapServers("172.22.13.101:9092").
pb:SetClientId("test client").
pb:SetBodySerializer(new StringSerializer()).
pb:SetKeySerializer(new StringSerializer()).
pb:SetProducerOption("message.timeout.ms", "10000").
producer = pb:Build().
recordBuilder = producer:RecordBuilder.
recordBuilder:SetTopicName("mytopic").
Find first customer.
recordBuilder:SetBody(name).
record = recordBuilder:Build().
response = producer:Send(record).
producer:Flush(1000).
repeat while not response:Completed:
pause .1 no-message.
end.
if response:Success then do:
message "Send successful" view-as alert-box.
end.
else do:
undo, throw new Progress.Lang.AppError("Failed to send the record: " +
response:ErrorMessage, 0).
end.
catch err as Progress.Lang.Error :
message err:GetMessage(1) view-as alert-box.
end catch.
finally:
delete object producer no-error.
end.
Po pierwsze wstawiam własny adres IP w metodzie SetBootstrapServers i nazwę topicu mytopic.
Potem ustawiam SetBodySerializer() (metoda ustawia proces serializacji dla treści wiadomości) na StringSerializer. Serializator zajmuje się konwersją danych na bajty w celu przesłania do topicu. OpenEdge udostępnia również MemptrSerializer i JsonSerializer, jak również tworzenie własnych niestandardowych serializatorów.
I wreszcie znajduję pierwszy rekord customer i ustawiam jego nazwę (name) jako wartość do przesłania.
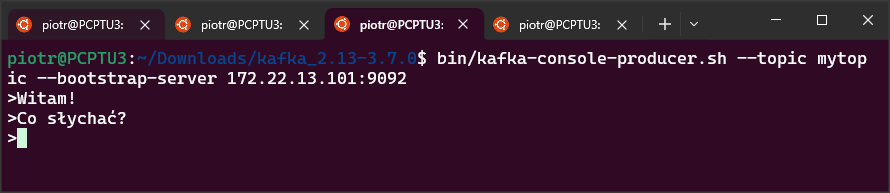
Po uruchomieniu procedury sprawdzam co pojawiło się w topicu Kafki. Na czerwono zaznaczyłem wartość przesłanej wartości (Lift Tours).

Teraz pora na odczyt wartości z topicu Kafki w procedurze ABL.
/* consumer.p */
block-level on error undo, throw.
using OpenEdge.Messaging.ConsumerBuilder from propath.
using OpenEdge.Messaging.IConsumer from propath.
using OpenEdge.Messaging.IConsumerRecord from propath.
using Progress.Json.ObjectModel.JsonConstruct from propath.
using Progress.Json.ObjectModel.JsonObject from propath.
var ConsumerBuilder cb.
var IConsumer consumer.
var IConsumerRecord record.
//var Progress.Lang.Object messageBody.
var char messageBody.
cb = ConsumerBuilder:Create("progress-kafka").
// Kafka requires at least one bootstrap server host and port.
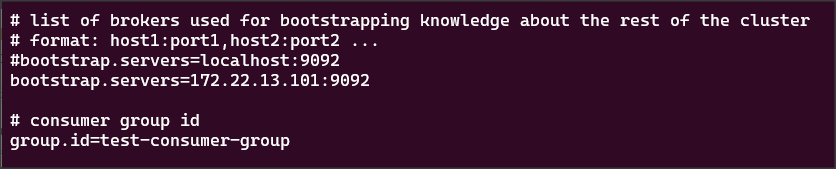
cb:SetConsumerOption("bootstrap.servers", "172.22.13.101:9092").
// Explicitly disable auto commit so it can be controlled within the application.
cb:SetConsumerOption("enable.auto.commit", "false").
// Identify the consumer group. The consumer group allows multiple clients to
// coordinate the consumption of multiple topics and partitions
//cb:SetConsumerOption("group.id", "my.consumer.group").
cb:SetConsumerOption("group.id", "test-consumer-group").
// Specify whether the consumer group should automatically be deleted when
// the consumer is garbage collected.
cb:SetConsumerOption("auto.delete.group", "true").
// Configure the consumer's deserializer in order to convert values from
// the network messages to string objects.
cb:SetConsumerOption("value.deserializer", "OpenEdge.Messaging.StringDeserializer").
// Set the consumer starting position to the most recent message
cb:SetConsumerOption("auto.offset.reset", "latest").
// identify one or more topics to consume
cb:AddSubscription("mytopic").
// build the consumer
consumer = cb:Build().
// loop forever receiving and processing records.
repeat while true:
// request a record, waiting up to 1 second for some records to be available
record = consumer:Poll(1000).
if valid-object(record) then do:
// acknowledge the message so the client can resume where it leaves off
// the next time it is started
consumer:CommitOffset(record).
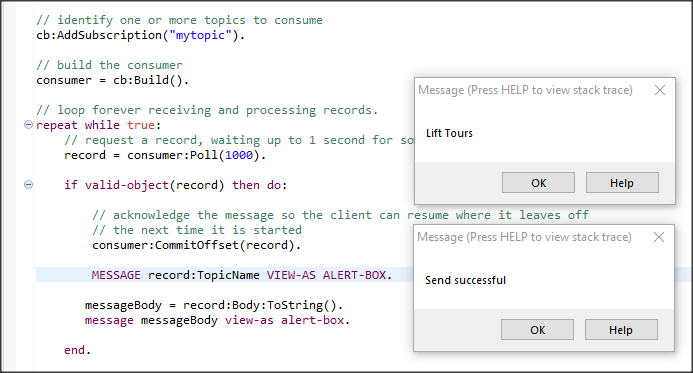
MESSAGE record:TopicName VIEW-AS ALERT-BOX.
messageBody = record:Body:ToString().
message messageBody view-as alert-box.
end.
end.
catch err as Progress.Lang.Error :
message err:GetMessage(1) view-as alert-box.
end catch.
finally:
delete object consumer no-error.
end.
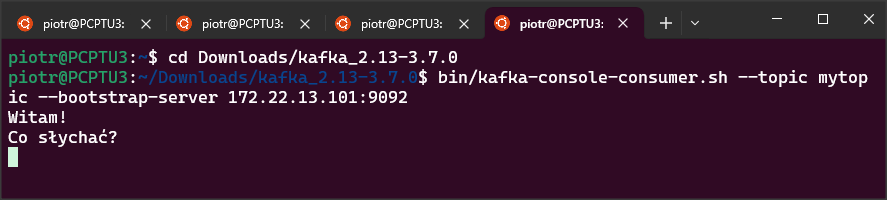
Uruchamiamy procedurę producer.p i consumer.p. Widać, że pierwsza wyświetla komunikat o poprawnym wysłaniu, a druga prawidłową wartość pobraną z kolejki.
Na koniec jeszcze jedna informacja związana z ustawianiem wartości parametrów. Otóż można to zrobić na dwa sposoby: poprzez użycie metod akceptujących wartości silnie typizowane (tzw. strongly-typed) lub używając par nazwa-wartość.
Obie poniższe linie kodu są równoważne:
pb:SetProducerOption("bootstrap.servers", "172.22.13.101:9092").
pb:SetBootstrapServers("172.22.13.101:9092").