Dynamic Data Masking II
Kolejnym krokiem jest zdefiniowanie masek dla wybranych pól. Maski te zasłaniają nieautoryzowanym użytkownikom część lub całą zawartość pola. Mamy cztery rodzaje takich masek: domyślna, częściowa (partial), literal, null.
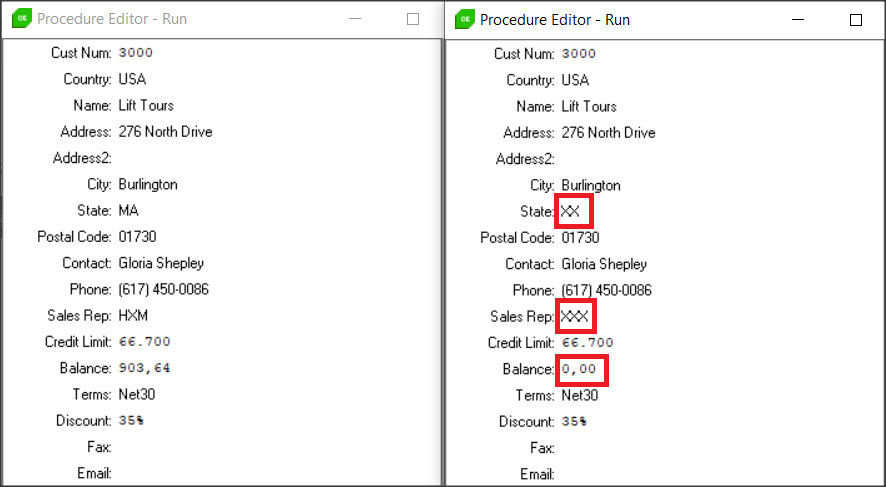
Wszystkie ustawienia DDM w ABL (tak jak w poprzednim artykule) realizujemy poprzez metody DataAdminService. Zaczynamy od maski domyślnej, w ktorej mamy małe pole do menewru. Pola znakowe są oznaczane jako XXX (liczba X zależy od maskowanych danych), pola decimal 0.00 itd. Maska jest ustawiana poprzez prefiks “D:”. Zaczniemy od pola Balance.
USING OpenEdge.DataAdmin.DataAdminService FROM PROPATH.
DEFINE VARIABLE service AS DataAdminService NO-UNDO.
DEFINE VARIABLE lResult AS LOGICAL NO-UNDO.
service = NEW DataAdminService(LDBNAME("DICTDB")).
lResult = service:setDDMConfig("Customer","Balance","D:","#DDM_SEE_ContactInfo").
Ustawmy taką samą maskę także na pola znakowe SalesRep i State.
Żeby ustawienia maskowania były widoczne trzeba aktywować usługę DDM w bazie poleceniem:
proutil sports2020 -C activateddm.

Do testowania użyjemy prostej procedury findCust.p.
// findCust.p FIND FIRST customer. DISPLAY customer EXCEPT comments WITH 1 COLUMN. PAUSE.
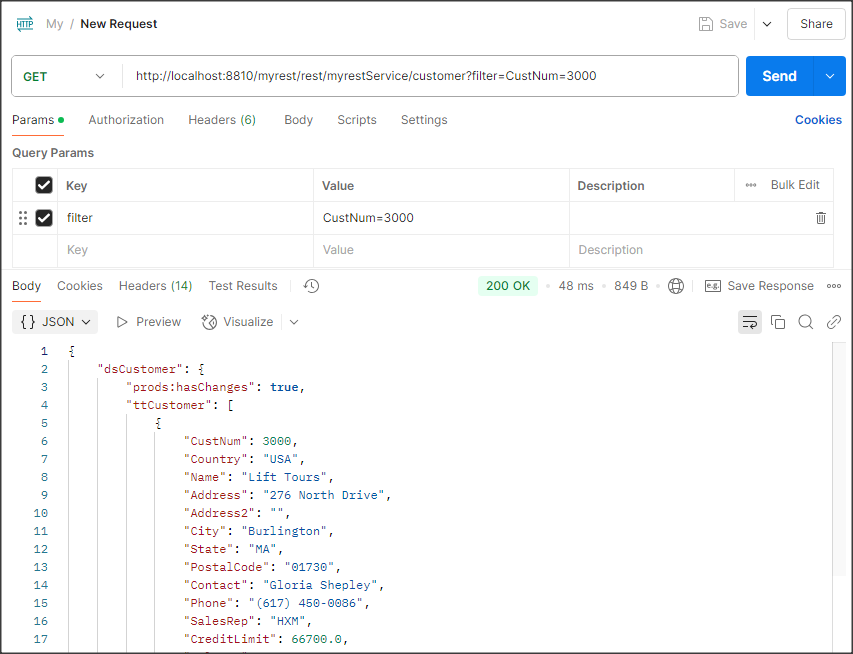
Uruchamiamy dwie sesje klienta z bazą sports2020 logując się raz jako Admin i raz jako User (patrz poprzedni artykuł). Poniżej widać porównanie danych dla obu sesji – różnice zaznaczyłem na czerwono.
Maska literal służy do maskowania danych gdy chcemy zamiast originalnej wartości podać własną. Należy pamiętać, że dla każdego rodzaju maski obowiązuje zasada zgodności typów, i tak tutaj dla pola znakowego City możemy podać własną maskę np. “UKRYTE“, dla pola PostalCode 00000 itd.
Maska literal jest ustawiana poprzez prefiks “L:”.
USING OpenEdge.DataAdmin.DataAdminService FROM PROPATH.
DEFINE VARIABLE service AS DataAdminService NO-UNDO.
DEFINE VARIABLE lResult AS LOGICAL NO-UNDO.
service = NEW DataAdminService(LDBNAME("DICTDB")).
lResult = service:setDDMConfig("Customer","City","L:UKRYTE","#DDM_SEE_ContactInfo").
lResult = service:setDDMConfig("Customer","PostalCode","L:00000","#DDM_SEE_ContactInfo").
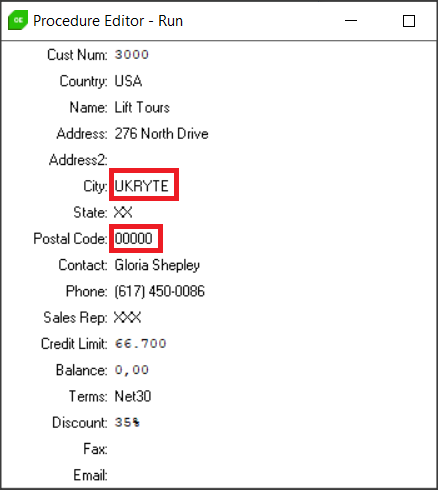
Pora przejść do najciekawszej maski, czyli częściowej, dającej najwięcej możliwości, ale stosowanej tylko dla pól znakowych.
Składnia maski wygląda tak: P:prefix,char[:maxchars][,suffix]
prefix – określa liczbę niezamaskowanych znaków, które mogą być wyświetlane na początku pola.
char[:maxchars] – określa pojedynczy znak ASCII, który ma być użyty do ukrycia wartości kolumny, maxchars (wartość opcjonalna) określa maksymalną liczbę znaków do zamaskowania przy użyciu podanego znaku ASCII, reszta ciągu jest przycinana.
[,suffix] – (wartość opcjonalna) określa liczbę znaków na końcu pola, które mogą być niezamaskowane.
USING OpenEdge.DataAdmin.DataAdminService FROM PROPATH.
DEFINE VARIABLE service AS DataAdminService NO-UNDO.
DEFINE VARIABLE lResult AS LOGICAL NO-UNDO.
service = NEW DataAdminService(LDBNAME("DICTDB")).
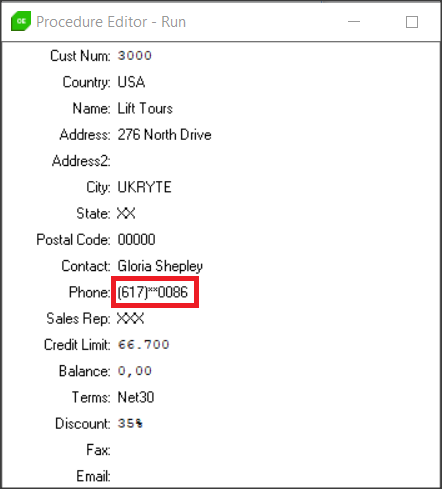
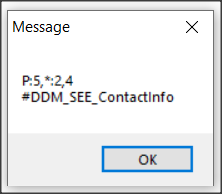
lResult = service:setDDMConfig("Customer","Phone","P:5,*:2,4","#DDM_SEE_ContactInfo").
Testujemy pole Phone. Działa to w następujący sposób: pierwsze 5 znaków jest niezamaskowana, podobnie jak ostatnie 4 znaki, to co w środku jest zamaskowane maksymalnie 2 znakami “*“. Jeśli długość pola będzie miała tylko 10 znaków to będzie wyświetlana tylko jedna gwiazdka itd.
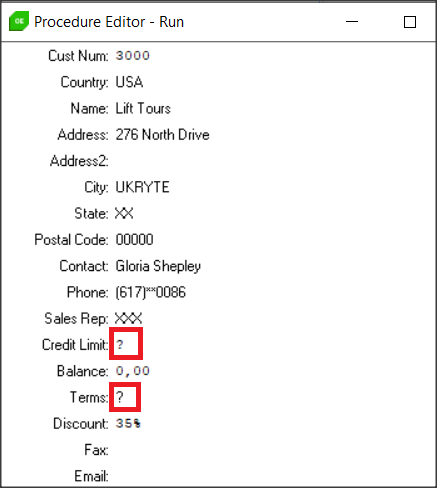
Ostatnim rodzajem maski jest null, którą można stosować dla każego typu danych. Zamaskowane wartości są wyświetlane jako “?“. Maskę null ustawiamy za pomocą prefiksu N:.
USING OpenEdge.DataAdmin.DataAdminService FROM PROPATH.
DEFINE VARIABLE service AS DataAdminService NO-UNDO.
DEFINE VARIABLE lResult AS LOGICAL NO-UNDO.
service = NEW DataAdminService(LDBNAME("DICTDB")).
lResult = service:setDDMConfig("Customer","CreditLimit","N:","#DDM_SEE_ContactInfo").
lResult = service:setDDMConfig("Customer","Terms","N:","#DDM_SEE_ContactInfo").
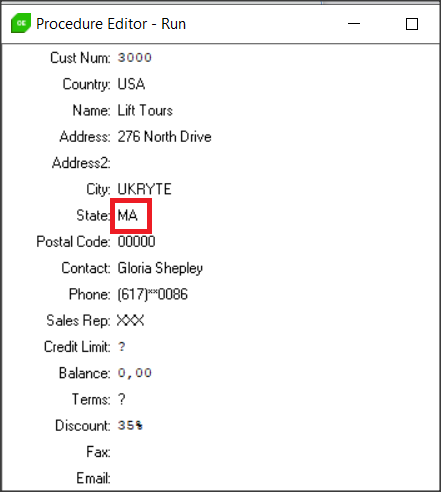
Jeśli trzeba usunąć maskowanie z pola musimy posłużyć się metodą unsetDDMMask. Usuńmy maskę np. z pola State.
USING OpenEdge.DataAdmin.DataAdminService FROM PROPATH.
DEFINE VARIABLE service AS DataAdminService NO-UNDO.
DEFINE VARIABLE lResult AS LOGICAL NO-UNDO.
service = NEW DataAdminService(LDBNAME("DICTDB")).
lResult = service:unsetDDMMask("Customer","State").
Przy pomocy metod DataAdminService można manipulować rolami, tagami autoryzacji itp. Możemy podejrzeć np. tag i maskę dla danego pola.
USING OpenEdge.DataAdmin.*.
VAR DataAdminService oDAS.
VAR CHARACTER cMask.
VAR CHARACTER cAuthTag.
oDAS = new DataAdminService (ldbname("DICTDB")).
oDAS:GetFieldDDMConfig ("Customer","Phone", OUTPUT cMask, OUTPUT cAuthTag).
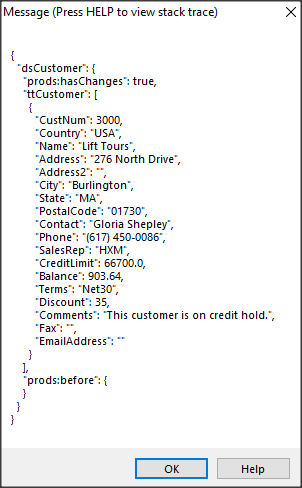
MESSAGE cMask SKIP cAuthTag
VIEW-AS ALERT-BOX.
Poniżej widać dane dla pola Phone.
OK, na tym na razie kończę. Do tematu powrócę jeśli będą od Was jakieś pytania.