Migracja do PASOE
O PASOE sporo pisałem. Wiadomo, w OE12 nie ma już klasycznego AppServera i trzeba podjąć decyzję o migracji aplikacji, a przed decyzją dobrze jest poznać za i przeciw nowego produktu.
Teraz jednak powracam do tematu samej migracji w szerszym kontekście (pisałem o podstawach migracji w 2017).
Korzyść z nowego AppServera widać już podczas instalacji: możemy wybrać czy instalowana instancja będzie deweloperska czy produkcyjna. Dla tej ostatniej dodajemy w komendzie parametr -Z prod i mamy instalowanie instancji z implementacją silniejszych zabezpieczeń niż dla wersji deweloperskiej. O samych zabezpieczeniach nie będę pisał ponieważ temu tematowi poświęciłem tutaj kilka wpisów.

Następnym krokiem jest migracja ustawień, czyli pliku z właściwościami. Istniejący plik ubroker.properties musi zostać przekonwertowany na nowy format używany przez PASOE openedge.properties.
Kolejność działania jest następująca: najpierw uruchamiamy polecenie paspropconv, które konwertuje właściwości z pliku ubroker.properties do tymczasowego pliku ubrokername.oemerge. Plik ten można dopasować do naszych potrzeb i włączyć ustawienia naszej nowej instancji do pliku openedge.properties.
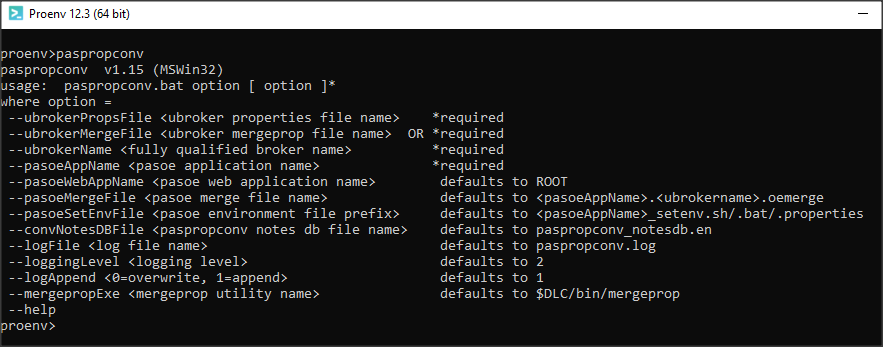
Komendę paspropconv uruchamiamy w podkatalogu conf dla instancji PASOE z przykładowymi parametrami, które są wymagane. Podwójne myślniki przed nazwą parametru wynikają stąd, że skrypt jest napisany w języku Perl.
--ubrokerPropsFile C:\classicapp\ubroker.properties --ubrokerName UBroker.AS.asbroker1 --pasoeAppName myprod
Pierwszy parametr określa ścieżkę do pliku z właściwościami dla klasycznego AppServera, drugi jest nazwą instancji tego AppServera, wreszcie trzeci określa nazwę nowej instancji PASOE.
Po uruchomieniu komendy w katalogu conf zostały utworzone poniższe pliki:
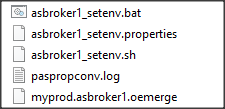
Dla nas istotny jest plik .oemerge. Niemal całą jego zawartość stanowi przewodnik po migracji, zawierający sekcje np:
Tryby pracy (operating modes) – zawiera porady dotyczące migracji istniejących trybów pracy (state-reset, state-aware, stateless, statefree) na tryby pracy w PASOE. Omówione są proste instrukcje, realizujące ten etap migracji, które wiążą i zwalniają bieżącą sesję ABL (były omawiane na blogu kilka lat temu).
Procedury zdarzeniowe (event procedures) – omawiane są stare i nowe procedury (agentStartupProc, sessionStartupProcParam) związane z inicjalizacją agenta wielo-sesyjnego oraz każdej sesji ABL.
# paspropconv v1.15 (MSWin32)
#
# Input arguments:
#
# ubrokerPropsFile = C:\classicapp\ubroker.properties
# ubrokerMergeFile =
# ubrokerName = UBroker.AS.asbroker1
# pasoeAppName = myprod
# pasoeWebAppName = ROOT
# pasoeMergeFile = myprod.asbroker1.oemerge
# pasoeSetEnvFile = asbroker1_setenv
# convNotesDBFile = C:\OPENED~1\bin\paspropconv_notesdb.en
# logFile = paspropconv.log
# loggingLevel = 2
#
# Operating Modes
# ---------------
#
# The classic AppServer supports 4 operating modes:
# state-reset
# state-aware
# stateless
# statefree
#
# In the classic AppServer, the operating mode is specified when the AppServer
# is deployed. Consequently, all ABL sessions supported by the AppServer
# employ the same operating mode.
#
# In PASOE, the operating mode of a session is not specified during deployment.
# As such, a single PAS server can support concurrent ABL sessions, each
# emulating the behavior of different classic operating modes.
#
# To support the different types of operating mode behavior
# provided in the various classic modes, some ABL code modifications
# may be required. It is recommended that these changes are made in
# the PASOE sessionConnectProc () and
# sessionDisconnProc () event procedures.
.......
[AppServer.Agent.myprod]
PROPATH=${CATALINA_BASE}/openedge,${CATALINA_BASE}/webapps/ROOT/WEB-INF/openedge,.....
agentMaxPort=2202
agentMinPort=2002
keyAlias=
keyAliasPasswd=
keyStorePasswd=
keyStorePath=${DLC}/keys/
noSessionCache=0
numInitialSessions=5
sessionActivateProc=
sessionConnectProc=
sessionDeactivateProc=
sessionDisconnProc=
sessionExecutionTimeLimit=0
sessionShutdownProc=
sessionStartupProc=
sessionStartupProcParam=
sessionTimeout=180
sslAlgorithms=
sslEnable=0
.......
Ostatnia sekcja nie jest komentarzem – zawiera zestaw właściwości, które powinny zostać scalone z plikiem openge.properties dla nowej instancji serwera.
Dalsze porady dotyczą ręcznej konfiguracji wynikającej z różnic w ścieżkach dostępu, architektury systemu operacyjnego, zmiennych środowiskowych, połączeń z bazami danych itd.
Dla pełniejszych informacji warto pobrać i przeczytać dokument: Quick Start: Moving Your Classic AppServer Applications to the Progress® Application Server for OpenEdge®.


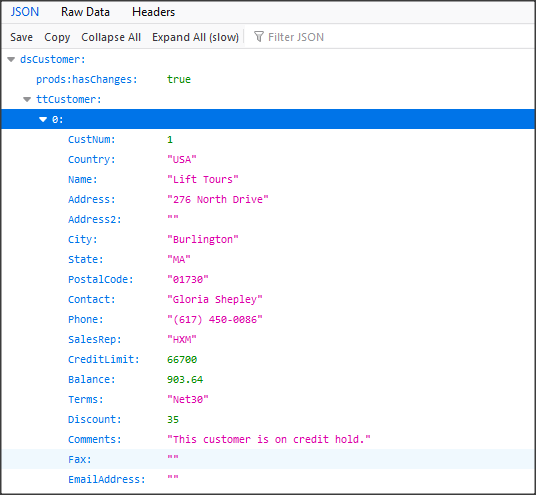
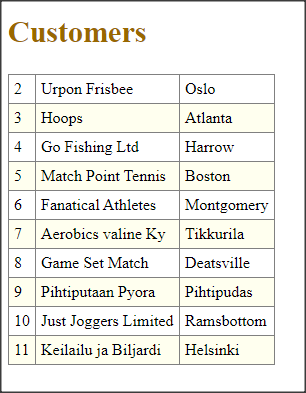
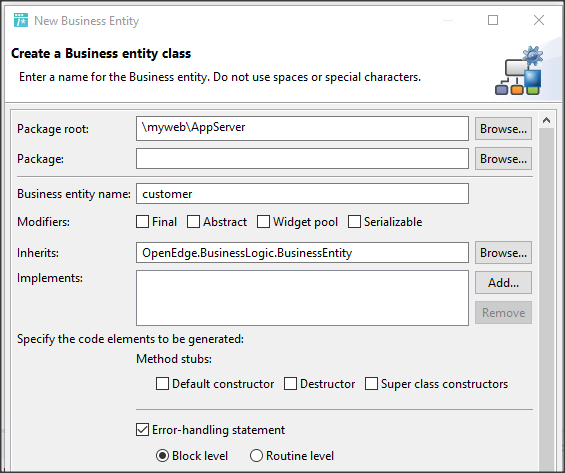
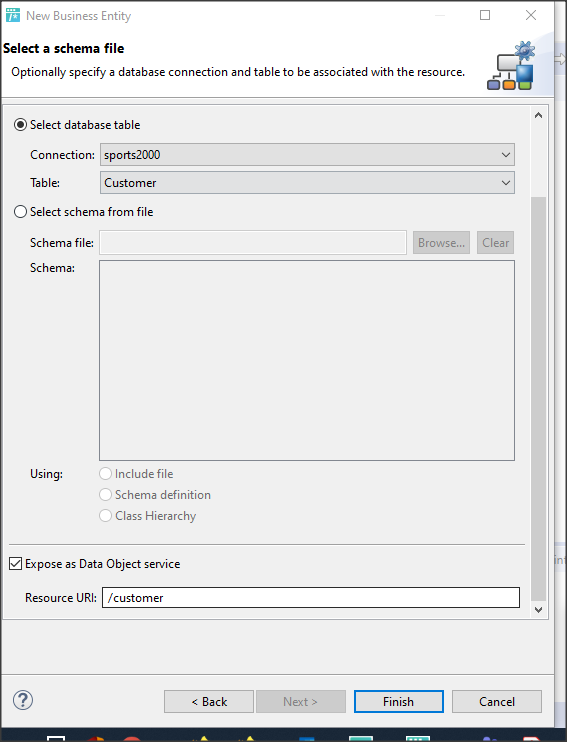
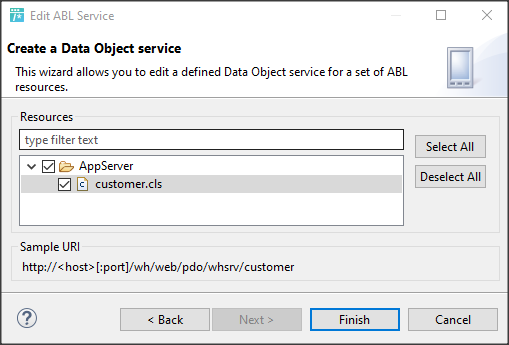
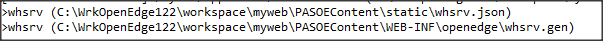
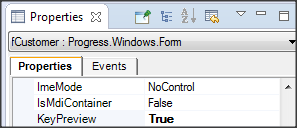
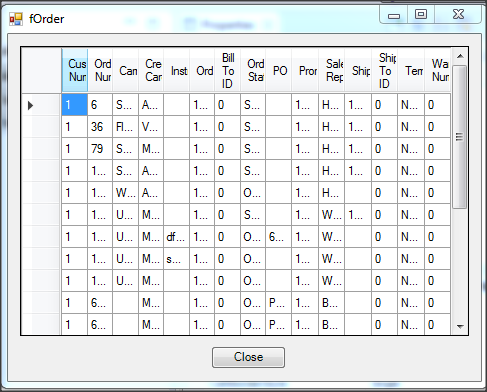
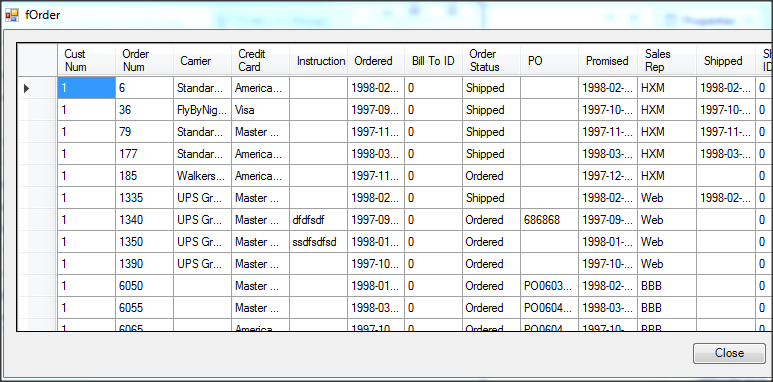
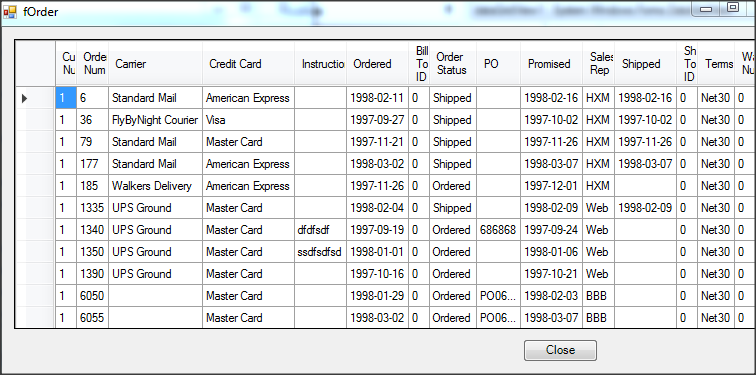
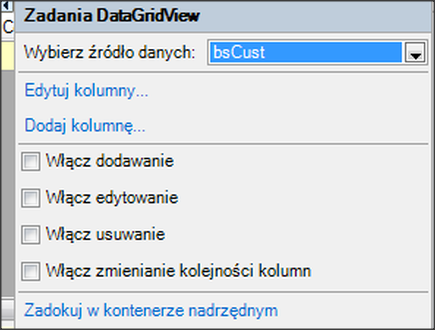
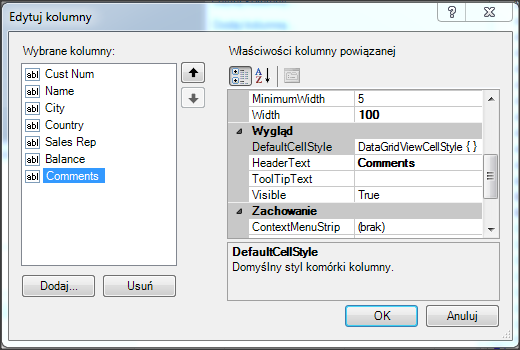
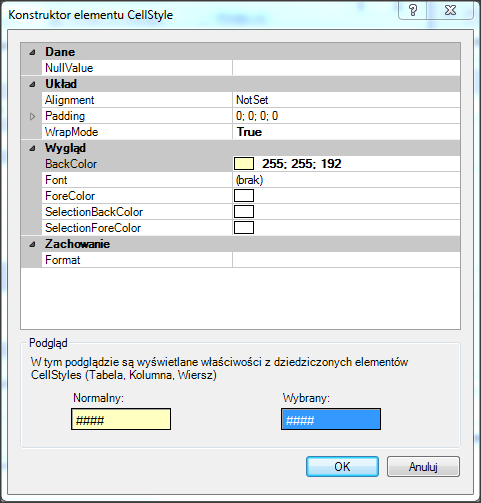
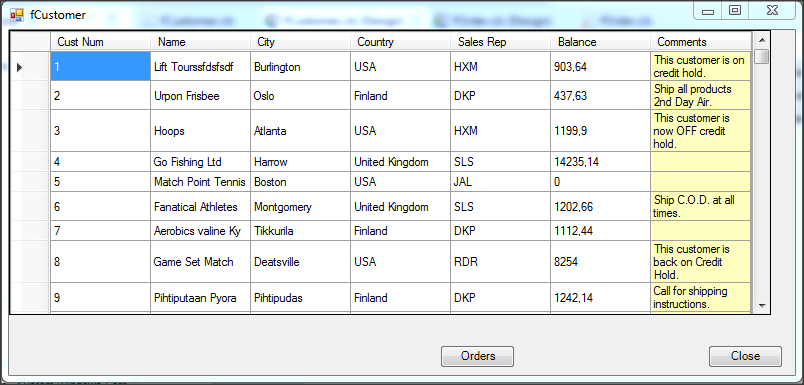
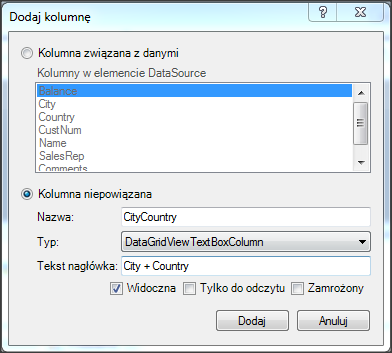
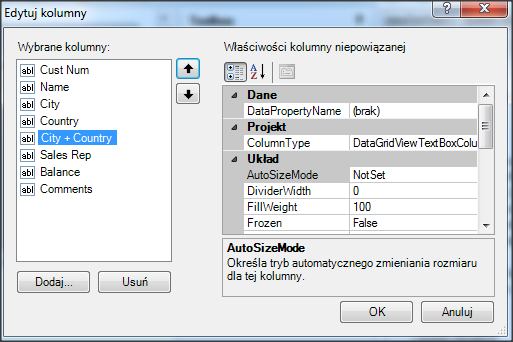
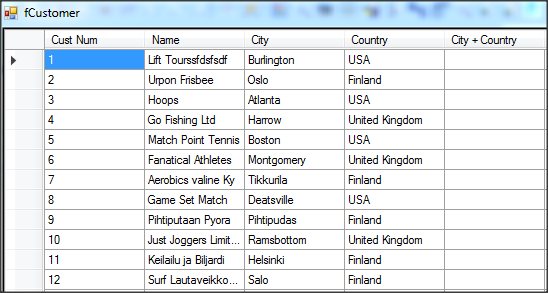

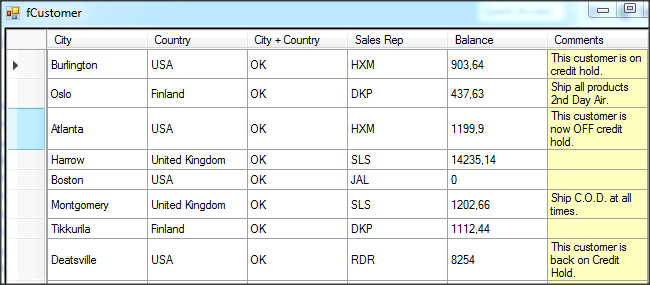
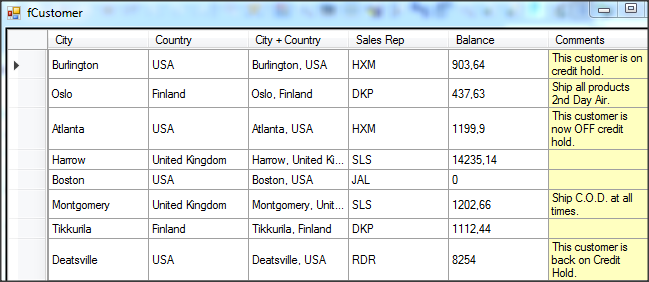
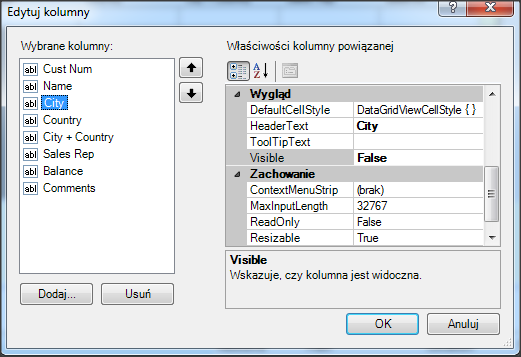
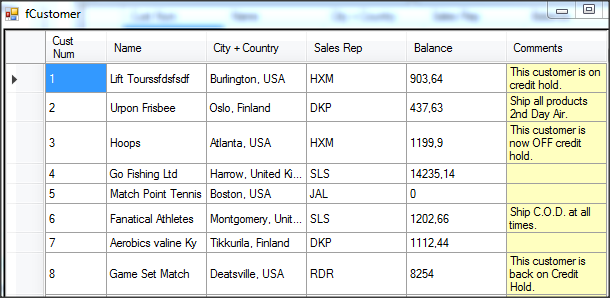
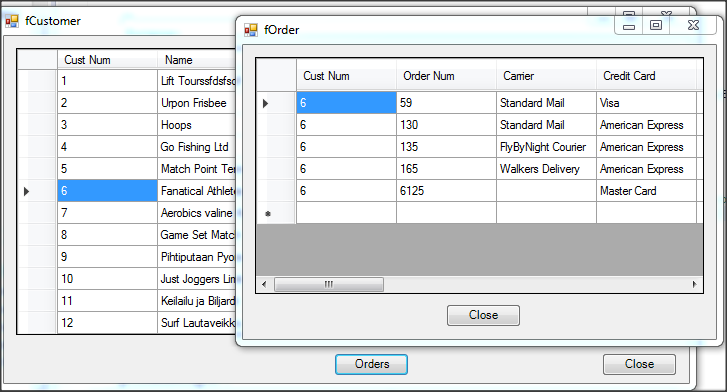
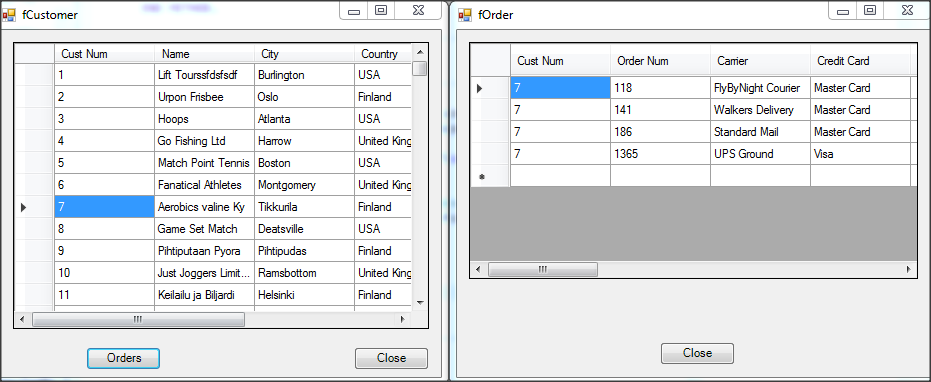
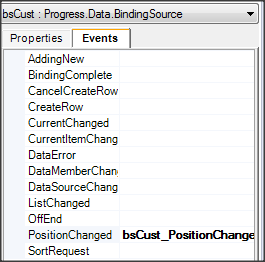
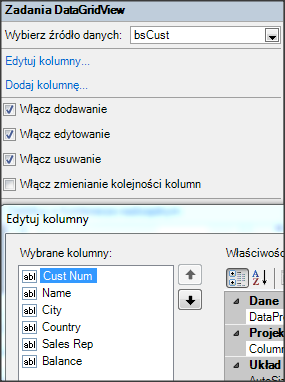
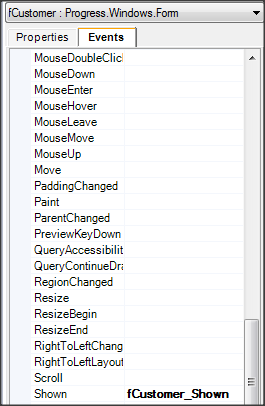
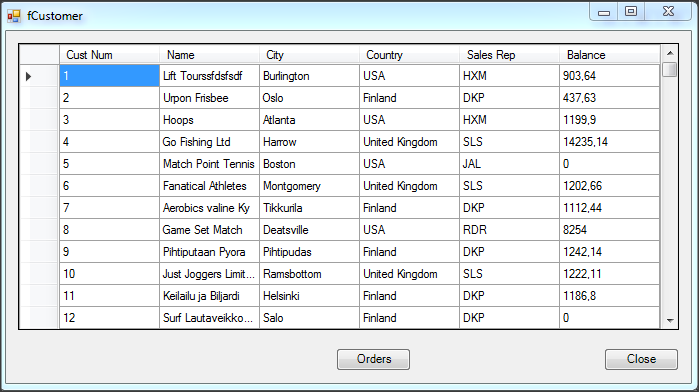 Wywołanie refreshData w konstruktorze może w niektórych przypadkach bardziej złożonych aplikacji być niekorzystne i generować błędy. To samo osiągniemy wstawiając wywołanie refreshData w metodzie formy Load lub Shown. Klikamy więc dwukrotnie w widoku Events na Shown; automatycznie jest wstawiona do naszego kodu metoda obsługi dla tego zdarzenia. Przenosimy tutaj wywołanie refreshData z konstruktora.
Wywołanie refreshData w konstruktorze może w niektórych przypadkach bardziej złożonych aplikacji być niekorzystne i generować błędy. To samo osiągniemy wstawiając wywołanie refreshData w metodzie formy Load lub Shown. Klikamy więc dwukrotnie w widoku Events na Shown; automatycznie jest wstawiona do naszego kodu metoda obsługi dla tego zdarzenia. Przenosimy tutaj wywołanie refreshData z konstruktora.