Strukturalna obsługa błędów w ABL cz. II
W poprzednim odcinku obiecałem napisać o tym jak utworzyć własną klasę obsługi błędów oraz pokazać, że strukturalną obsługę błędów można stosować także w przypadku procedur uruchamianych na serwerze aplikacji. Obie te kwestie pokażę na jednym przykładzie.
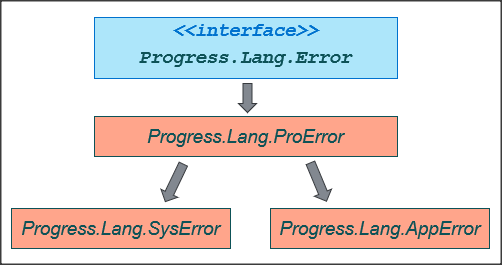
W Developer’s Studio klasę definiujemy najwygodniej przy pomocy wizarda, tak jak każda inną klasę. Musimy pamiętać, że dziedziczy ona z klasy Progress.Lang.AppError oraz że trzeba zdefiniować ją jako Serializable, co oznacza, że instancja klasy może być przekazywane przez wartość pomiędzy sesjami AVM (ABL Virtual Machine).
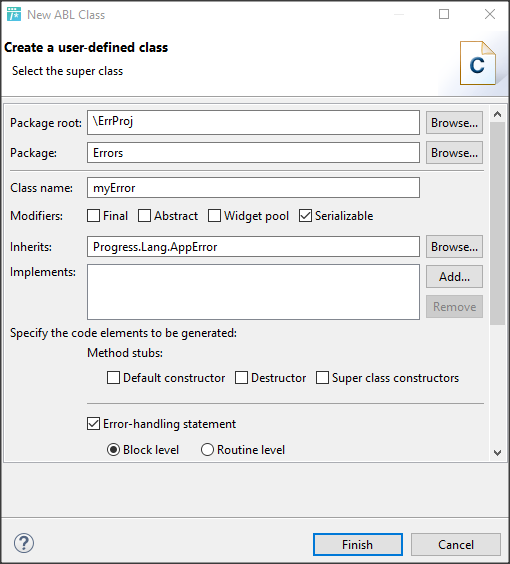
Poniżej widzimy gotową klasę Errors.myError zawierającą właściwości: Errormessage, ErrorNum oraz ProcName oraz dwie metody GetErrorMessage() i GetVerboseErrorMessage(). Posłużą one do własnej obsługi błędów.
Pierwsza metoda zwraca jedynie komunikat wraz z numerem błędu. GetVerboseErrorMessage() zawiera także nazwę procedury, w której ten błąd wystąpił. Gdybyśmy tworzyli program złożony z obiektów moglibyśmy użyć nazwy klasy i metody aby mieć więcej informacji o lokalizacji wystąpienia błędu itp.
USING Progress.Lang.*.
USING Progress.Lang.AppError.
BLOCK-LEVEL ON ERROR UNDO, THROW.
CLASS Errors.myError INHERITS AppError SERIALIZABLE:
DEFINE PUBLIC PROPERTY ErrorMessage AS CHARACTER NO-UNDO
GET.
SET.
DEFINE PUBLIC PROPERTY ErrorNum AS INTEGER NO-UNDO
GET.
SET.
DEFINE PUBLIC PROPERTY ProcName AS CHARACTER NO-UNDO
GET.
SET.
CONSTRUCTOR PUBLIC myError (
INPUT pErrorNum AS INTEGER,
INPUT pErrorMessage AS CHARACTER,
INPUT pProcName AS CHARACTER):
SUPER ().
ErrorNum = pErrorNum.
ErrorMessage = pErrorMessage.
ProcName = pProcName.
END CONSTRUCTOR.
METHOD PUBLIC CHARACTER GetErrorMessage( ):
DEFINE VARIABLE res AS CHARACTER NO-UNDO.
res = ErrorMessage + ". " + STRING(ErrorNum).
RETURN res.
END METHOD.
METHOD PUBLIC CHARACTER GetVerboseErrorMessage( ):
DEFINE VARIABLE res AS CHARACTER NO-UNDO.
res = ErrorMessage + ". " + STRING(ErrorNum) + ". Proc: " + ProcName.
RETURN res.
END METHOD.
END CLASS.
Poniższy przykład jest analogiczny do tego z poprzedniego odcinka – został zmodyfikowany do uruchomienia na serwerze aplikacji, oczywiście z własną obsługą błędów.
USING Errors.myError.
VAR INT i = 1.
DEFINE VARIABLE hServer AS HANDLE NO-UNDO.
DEFINE VARIABLE lReturn AS LOGICAL NO-UNDO.
CREATE SERVER hServer.
lReturn = hServer:CONNECT("-URL http://localhost:8810/apsv
-sessionModel Session-managed").
IF NOT lReturn THEN DO:
DELETE OBJECT hServer NO-ERROR.
RETURN ERROR "Failed to connect to the ABL web application: " + RETURN-VALUE.
END.
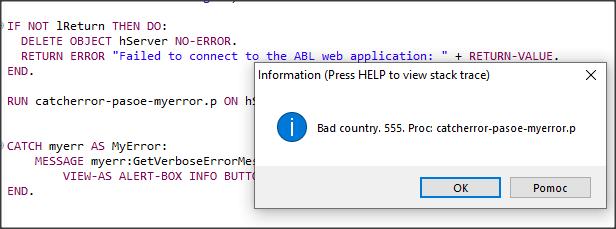
RUN catcherror-pasoe-myerror.p ON hServer (INPUT 3000).
CATCH myerr AS MyError:
MESSAGE myerr:GetVerboseErrorMessage()
VIEW-AS ALERT-BOX INFO BUTTONS OK.
END.
/************************************************************/
/* catcherror-pasoe-myerror.p */
BLOCK-LEVEL ON ERROR UNDO, THROW.
USING Errors.myError.
DEFINE INPUT PARAMETER icustNum AS integer.
DEFINE VARIABLE ProcName AS CHARACTER.
FIND customer WHERE customer.custnum = icustNum.
if country NE "Poland" THEN DO:
ProcName = ENTRY(1, PROGRAM-NAME(1),' ').
UNDO, THROW NEW myError(555, "Bad country", ProcName).
END.
Ponieważ użyłem metody GetVerboseErrorMessage() otrzymuję cały komunikat z nazwą procedury w której wystąpił błąd.