Memory Profiler 1
W OpenEdge od wersji 12.8.9 mamy długo oczekiwane narzędzie Memory Profiler.
Umożliwia ono analizę wykorzystania pamięci przez aplikację w funkcji czasu a także w określonych interwałach, umożliwiając wizualizację wykorzystania pamięci przez kod aplikacji.
Wycieki pamięci występują, gdy aplikacja nie zwalnia niepotrzebnej już pamięci. W konsekwencji wykorzystanie jej przez aplikację rośnie z czasem, co może prowadzić do spadku wydajności, a ostatecznie do wyczerpania zasobów pamięci i awarii aplikacji lub systemu. Wycieki pamięci są szczególnie problematyczne w długo działających aplikacjach lub systemach wymagających wysokiej wydajności i niezawodności działania.
Memory Profiler zapewnia wizualizację wykorzystania pamięci i pomaga programistom ABL w skutecznym wykrywaniu i diagnozowaniu problemów z wykorzystaniem pamięci w ich aplikacjach ABL.
Korzyści płynące z używania narzędzia:
Zapewnienie stosowania najlepszych praktyk — identyfikując obszary wymagające odpowiednich operacji czyszczenia i zachęcając do stosowania efektywnych praktyk kodowania.
Z technicznego punktu widzenia to narzędzie jest specjalną instancją PASOE, którą możemy utworzyć korzystając z dostarczonych plików.
Spakowane pliki te znajdują sie w katalogu [DLC]/servers/redist/oemp-[wersja oe].zip (np. oemp-12.8.9.zip).
Plik zip kopiujemy do jakiegoś katalogu z pełnymi uprawnieniami i rozpakowujemy, przechodzimy do podkatalogu oemp\bin, a następnie w oknie komend proenv uruchamiamy komendę oemp install.
Należy pamiętać żeby katalogiem, w którym umieścimy pliki nie byl podkatalog oemp w lokalizacji working directory ponieważ pojawi się wtedy poniższy błąd:
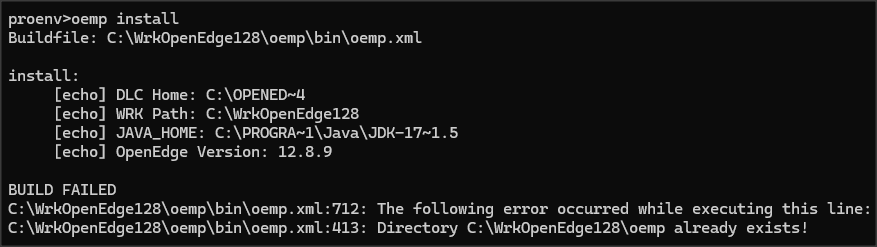
Jak wybrałem podkatalog c:\oemp i wszystko poszło jak po maśle.
Proces instalacji jest dość długi, u mnie trwał prawie 5 minut.
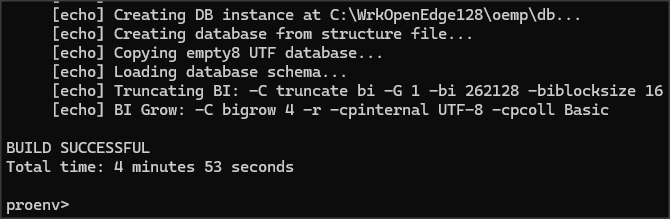
Po zakończonej instalacji mamy nową instancję PASOE oemp, która odwołuje się do bazy danych /db/reportdb. Narzędzie startujemy poleceniem: oemp startup.
Kiedy instancja jest już uruchomiona, wpisujemy następujący URL w przeglądarce: http://localhost:8880 i dostajemy główny widok Memory Profilera.
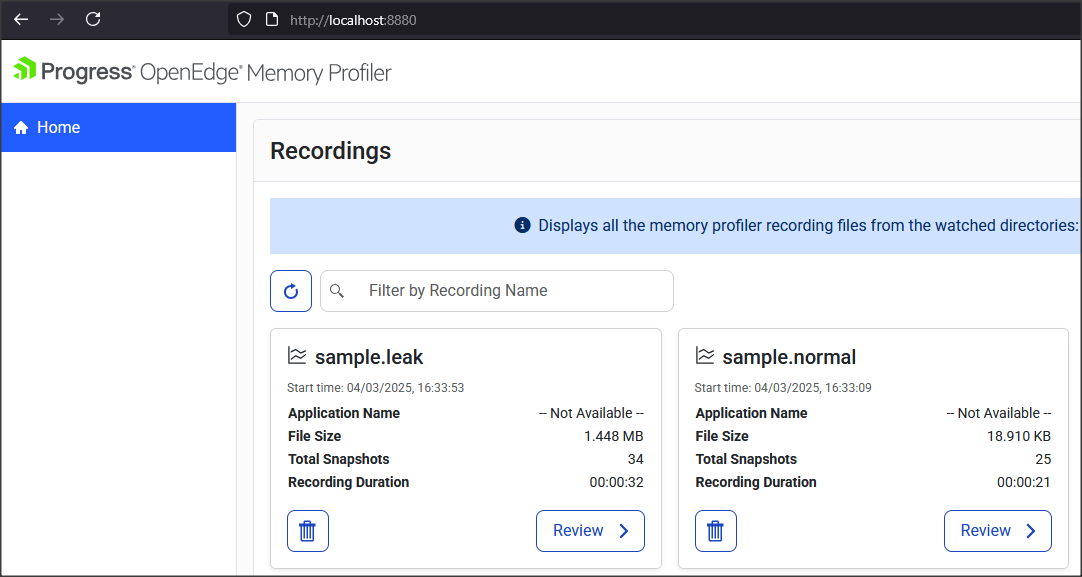
Niedługo napiszę jak korzystać z OE Memory Profilera.