Podpisane biblioteki procedur ABL
Dziś napiszę wstęp o zabezpieczeniach r-kodów w tzw. podpisanych bibliotekach archiwum procedur. Temat ten wypłynął podczas kwietniowego spotkania World Tour i byłem poproszone o napisanie trochę więcej informacji niż było to w prezentacji.
Biblioteki archiwum ABL to zbiór r-kodów (rozszerzenie .apl), podobnie jak dobrze znane biblioteki .pl ale obsługują także podpisywanie i weryfikację r-kodów.
Podpisany plik archiwum gwarantuje, że żaden r-kod nie został uszkodzony ani naruszony. Jest to bardzo istotne np. podczas przeprowadzanych zewnętrznych audytów aby mieć pewność, że aplikacje przejdą kontrolę bezpieczeństwa.
Deweloperzy dostają dwa narzędzia uruchamiane z wiersza poleceń PROPACK i PROSIGN. Tworzą one cyfrowo podpisane archiwum oparte na standardzie Java JAR.
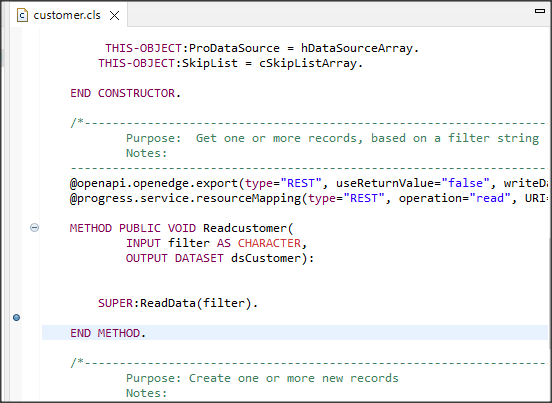
Zacznijmy od spakowania dwóch plików procedur findcustomer.r i updatecustomer.r wykorzystując komendę PROPACK. Nasz plik wynikowy bedzie miał nazwę cust.apl. Pozostaje do określenia ważny atrybut sygnatury. Może on mieć wartość open (pliki archiwum nie muszą być podpisane) lub required (podpis jest wymagany). Użyję tutaj domyślnej wartości open. Przykład komendy będzie wyglądał następująco:
propack --create --file=cust.apl --vendor "PSC" --signature=open .
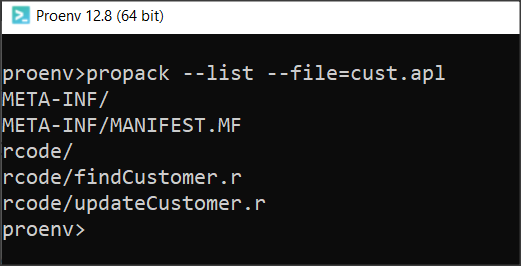
Żeby sprawdzić jakie pliki znajdują się w archiwum uruchamiamy komendę z opcją –list:
propack --list --file=cust.apl
Widać, że w bibliotece znajduje się plik MANIFEST.MF
Zawiera on informacje na temat archiwum, a w przypadku podpisanej biblioteki także sygnatury r-kodów (o czym za chwilę).
Zobaczmy teraz co się stanie jeśli utworzę taką bibliotekę z parametrem signature=required.
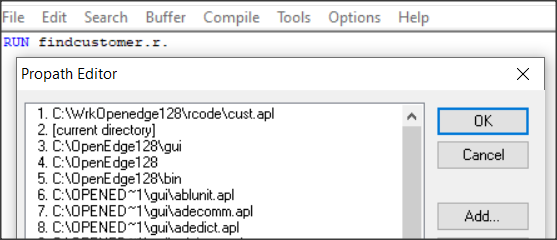
Dodaję nazwę nowej biblioteki w Protools do PROPATH i uruchamiam prostą komendę.
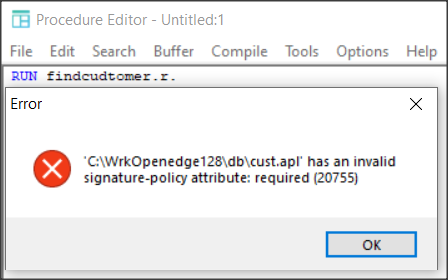
Dostajemy błąd ponieważ plik musi być podpisany.
Wróćmy do pliku z sygnaturą typu open i zajmijmy się podpisaniem biblioteki. Przed uzyskaniem certyfikatu cyfrowego należy utworzyć magazyn kluczy do przechowywania certyfikatów własnych i z urzędu certyfikacji (CA). Utworzenie magazynu kluczy powoduje również umieszczenie w magazynie certyfikatu z podpisem własnym (self-signed) i pary kluczy (publiczny-prywatny). Nam dla testów będzie wystarczył certyfikat self-signed.
Użyjemy poniższej komendy pamiętając, że w oknie komend musi to być ciąg znaków bez znaków końca linii.
keytool -genkey -dname "CN=Host, OU=Education O=PSC, L=Warsaw, S=Mazovia, C=Poland" -alias server -keystore myKeystore.jks -storepass mykeystorepass1 -validity 90 -keyalg RSA -keysize 4096
Magazyn klucza jest już wygenerowany (.jks). Zapisujemy wartość aliasu i hasła do magazynu.
Teraz możemy użyć komendy PROSIGN.
prosign --archive cust.apl --signedarchive signedcust.apl --alias server --keystore myKeystore.jks --storepass mykeystorepass1
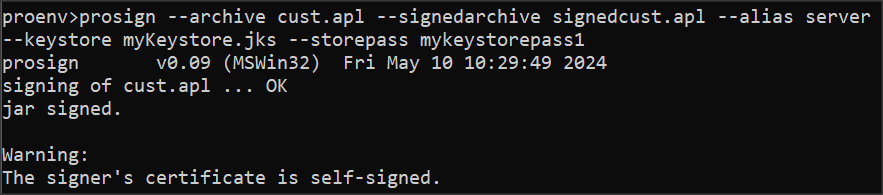
Biblioteka jest już podpisana ale dostaliśmy ostrzeżenie, że certyfikat jest self-signed i w środowisku produkcyjnym musimy zadbać o taki, który jest wydany przez oficjalny urząd (CA).
Zobaczmy teraz zawartość pliku MANIFEST.MF. Zawiera on na końcu funkcje skrótu SHA-256 dla obu r-kodów, gwarantując ich oryginalną zawartość.
Manifest-Version: 1.0 Implementation-Title: cust.apl Implementation-Vendor: PSC Implementation-Version: 0.0.0.0 Component-Name: cust.apl Package-Type: apl Signature-Policy: open Validation-Policy: warn Build-OS: all Build-Date: 2024-05-10T14:57:39.157+01:00 OpenEdge-Tool: propack v1.00 (MSWin32) OpenEdge-Version: 12.8 Created-By: 17.0.10 (Oracle Corporation) Name: findCustomer.r SHA-256-Digest: 1wpcgS+b6ya5OvqTjUek29hJdnqWNsjdRBJTPzYDCyo= Name: updateCustomer.r SHA-256-Digest: fKk6cX6dlJsN8VxgKzdbjM1XaXQRL/N3sdlHySHb0vE=