
Promon – analiza danych 2
Powracając do tematyki związanej z tym najbardziej znanym narzędziem dla administratorów baz, chciałbym napisać dwa słowa o ukrytej opcji, którą, jak się okazuje, nie wszyscy znają.
Kiedyś była to opcja R&D, niewidoczna z głównego menu ale to było dawno temu.
Drugie menu było bardziej ukryte. Trzeba było napisać devdbh, Enter i następnie 6.
Obecnie w nowym promonie ta opcja jest widoczna właśnie na pozycji 6 w meny R&D chociaż możemy wejść do niej także “po staremu”.
Zawiera zaawansowane opcje dogłębnego monitorowania aktywności i wydajności systemu baz danych OpenEdge.
Jak widać lista jest całiem długa, ale są to informacje dla zaawansowanych administratorów, lub raczej dla techsupportu PSC. Może się zdarzyć że będziemy poproszeni o przesłanie konkretnych danych z tej listy.
Powróćmy do danych, które możemy pobrać do własnej analizy. Myślę, że jednymi z najważniejszych są te związane z checkpointami.
Uruchamiam własny program generujący transakcje w bazie testowej (kopia sports2000) i wchodzę do promona.
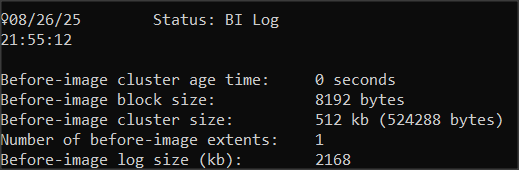
W opcji R&D -> 1. Status Displays -> 9. BI Log sprawdzam parametry zapisu BI na dysku. Blok BI ma 8kB, a cluster tylko 512 kB (domyślna wartość). Zobaczmy jaki to będzie miało efekt w działaniu.
Przechodzę do głównego menu, a następnie 3. Other Displays -> 4. Checkpoints.
Popatrzmy na poniższą analizę. Nie wygląda to dobrze…
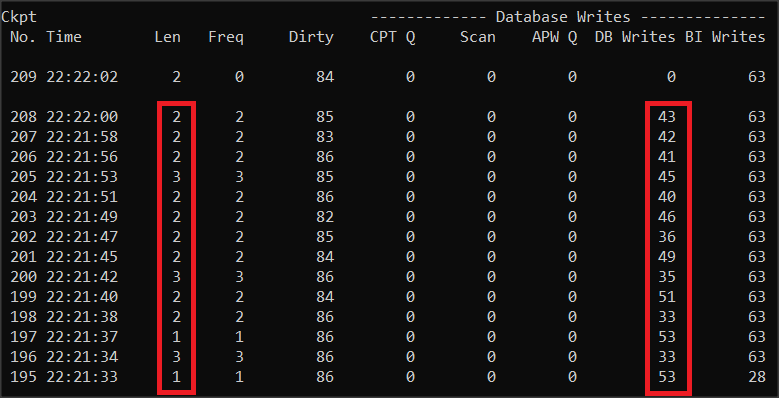
Co oznaczają niektóre kolumny (wg dokumentacji):
Dirty – liczba zmodyfikowanych buforów zaplanowanych do zapisania.
CPT Q – Liczba buforów zapisanych z kolejki checkpoint przez procesy APW.
Scan – Liczba buforów zapisanych przez procesy APW podczas cyklu skanowania.
APW Q – Liczba buforów zapisanych przez kolejkę APW i zastąpionych w łańcuchu LRU przez procesy APW.
DB Writes – Całkowita liczba buforów bazy danych zapisanych na końcu checkpointu.
Administratorzy baz chcą aby odstęp między checkpointami (kolumna Len) był rzędu kilku minut, a tu mamy 2 sekundy. Ponadto podczas checkpointu jest nienaturalnie duża ilość zapisów na dysk – kolumna DB Writes (ten parametr w starszych wersjach jest określany jako Flushes). Tak liczne zapisy powodują spadek wydajności.
Nie uruchomiłem jeszcze procesu APW, więc kolejka APW jest pusta, ale i tak widać od razu, że trzeba koniecznie wydłużyć cluster. Zwiększę go zatem z 0.5 MB do 16 MB. Rozmiar bloku BI zwiększę przy okazji z 8 KB do 16 KB.
proutil [baza] -C truncate bi -bi 16384 -biblocksize 16
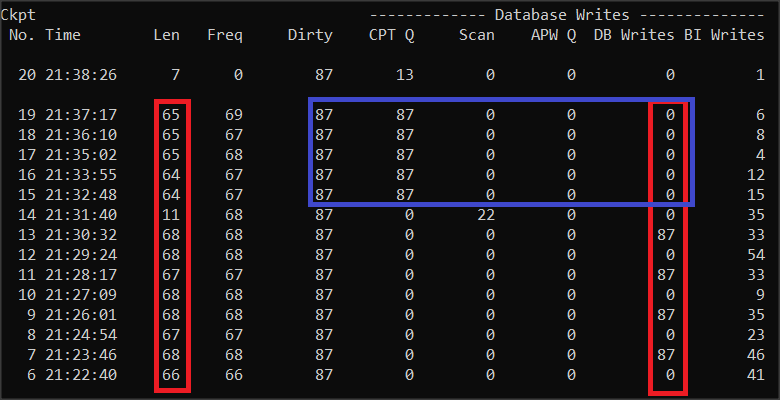
Ponieważ rozmiar clustra został zwiększony 32 razy to dostęp między checkpointami zwiększy się z 2-3 sekund do ok. 70 sekund. Po odczekaniu zobaczmy jak teraz wygląda analiza checkpointów.
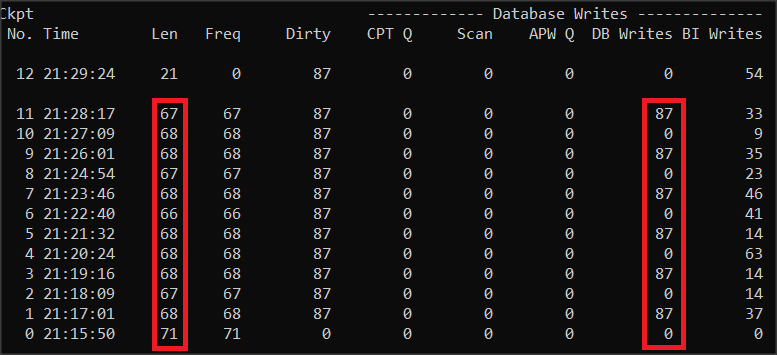
Zobaczmy, że wartości Dirty nie przekraczają wartości DB Writes, jak poprzednio. Oznacza to, że jest dość czasu podczas checkpointu żeby zapisy zostały dokonane. Jednakże duża liczba tych zapisów może powodować spowolnienie systemu podczas checkpointu. Nie mamy tu na razie procesów asynchronicznych (tylko serwer Enterprise) i kolumna CPT Q pokazuje same zera.
A teraz co się zmieni po uruchomieniu procesu APW (niebieska ramka). Wszystkie bufory do zapisu są umieszczone w kolejce checkpoint i zapisane przez procesy APW tak, że podczas checkpointu nie ma już żadnych zapisów i system nie będzie spowalniał
Metoda wydłużenia czasu między checkpointami jest dość prosta i możemy pokusić się o dalsze zwiększenie clustra BI żeby czas wynosił tutaj 2-3 a nawet 5 minut. Pytanie tylko czy nasze dyski są dostatecznie szybkie aby temu podołać. Clustra nie można zwiększać bez końca bez żadnych konsekwencji.
W następnym wpisie napiszę o prostym teście jak można taką graniczną wartość określić.
Na koniec jeszcze mała uwaga dotycząca zbierania danych z promona poprzez skrypt. Większość parametrów znajduje się w tablicach VST, zawierających tylko jeden rekord (podawana wartość to różnica wartości z danego pola w czasie) ale czasem tych rekordów jest więcej, jak w przypadku checkpointów. Nie ma dla nich w promonie opcji automatycznego odświeżania. Najłatwiej jest oczywiście napisać program w ABL ale jeśli nie mamy takiej możliwości, to obliczamy po ilu minutach zapełnią się dane wszystkich checkpointów na ekranie (tutaj ok. 15 minut) i ustawiamy uruchomienie skryptu zapisującego tylko ten ekran (np. w cronie) co ten czas.