Promon – analiza danych 3
Dziś napiszę znowu o promonie odpowiadając przy okazji na kilka Waszych pytań, za które bardzo dziękuję.
Pierwsze dotyczy strojenia parametru -spin (tylko dla licencji serwera Enterprise).
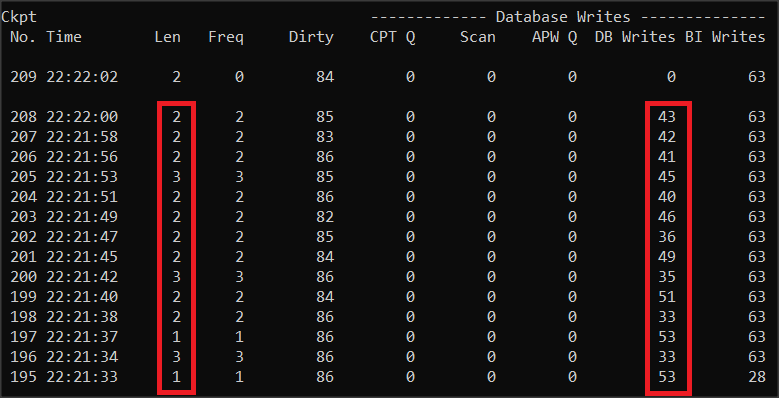
Parametr „Spin Lock Retries” (–spin N) służy do określania, ile razy proces próbuje uzyskać zatrzask (latch) do zablokowanego zasobu w pamięci współdzielonej przed “pójściem na drzemkę”. Po wstrzymaniu procesu na określoną liczbę milisekund, proces uruchamia się ponownie i ponownie próbuje uzyskać zatrzask. Proces ten bardzo obciąża procesor dlatego uzywa się go wyłącznie w maszynach wieloprocesorowych, choć w starych systemach jednoprocesorowych zalecano użycie tego parametru z wartością 1, ze względu na to, że i tak był on szybszy niż mechanizm oparty na semaforach. Liczba nieudanych prób uzyskania zatrzasku określana jest w promonie Latch timeouts. Im jest ich więcej tym częściej dochodzi do konfliktów między zatrzaskami i tym gorsza jest wydajność bazy danych.
Domyślne obliczenie brokera bazy danych to 6.000 x liczba procesorów zgłoszonych przez system operacyjny, co prawdopodobnie było odpowiednie, gdy na serwer przypadało 2 lub 4 rdzenie/procesory, ale teraz, w przypadku maszyn wielordzeniowych z 16 lub więcej rdzeniami, automatycznie obliczona liczba jest prawdopodobnie zbyt wysoka.
Np. w moim laptopie procesor ma 4 rdzenie i 8 wątków i parametr ten ma domyślną wartość 48.000.
Miejcie więc na względzie aby sprawdzić tę wartość w promonie:
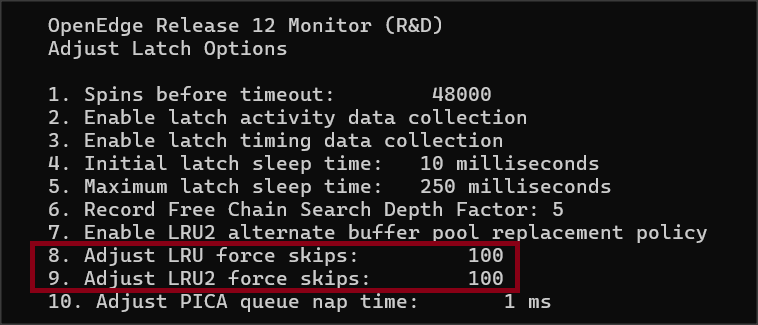
R&D -> 4. Administrative Functions 4. Adjust Latch Options
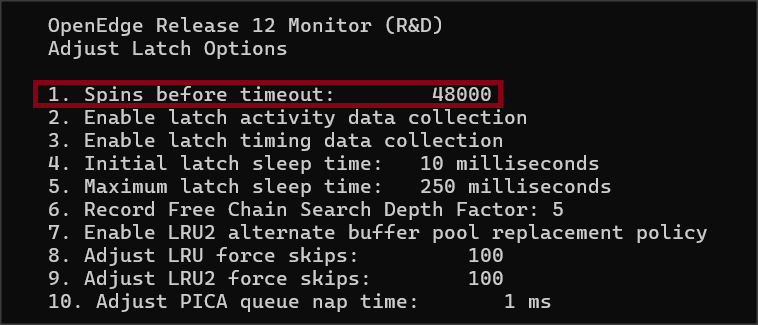
W tym samym miejscu możemy zmienić tę wartość online (podopcja 1).
Expert z White Star Software uważa, że wartości z przedziału 5.000 do 20.000 są wystarczające dla zdecydowanej większości baz danych, więc nie ma co szaleć. Należy przede wszystkim monitorować wykorzystanie CPU i w razie gdy osiąga ono duże wartości (90% lub więcej) zmniejszyć -spin online.
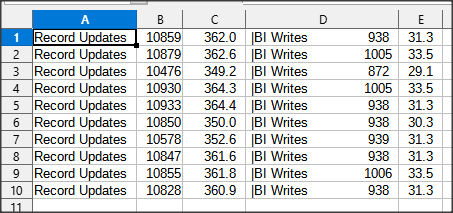
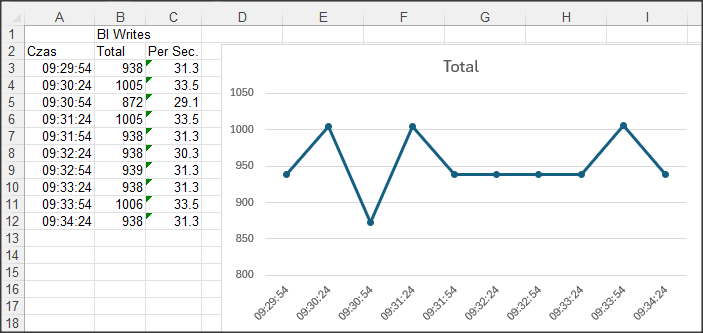
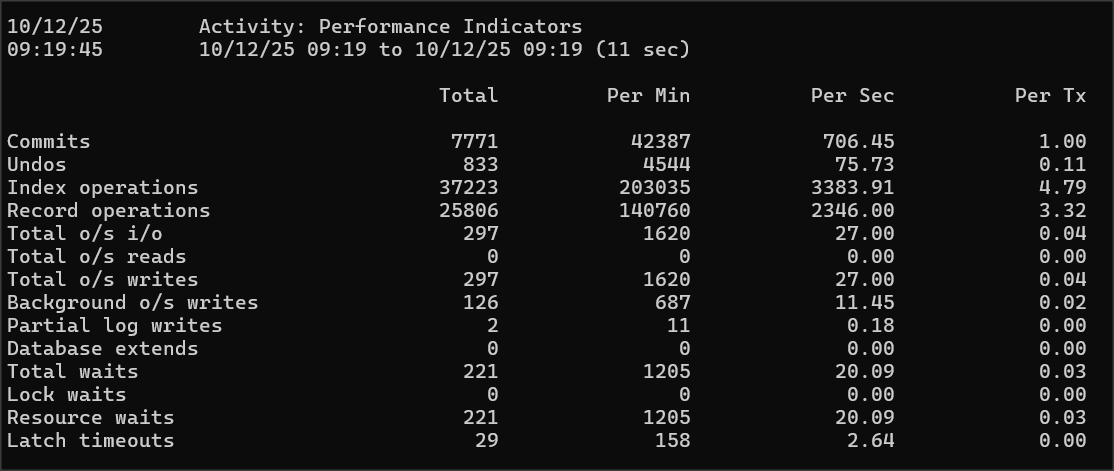
Analizę timeoutów możemy podejrzeć na poniższym ekranie promona – ostatni wiersz.
R&D -> 3. Other Displays -> 1. Performance Indicators -> Latch timeouts
Drugim parametrem, o którym chcę tutaj napisać jest -lruskips dostępny także tylko dla serwera Enterprise i ma związek z zatrzaskami przy próbie dostępu do zasobu w puli buforów.
Łańcuch LRU (Least Recently Used) składa się ze wskaźników do buforów w puli i przy każdym odczycie z tej puli (dla -lruskips = 0) potrzebne jest uzyskanie zatrzasku aby uaktualnić ten łańcuch. Jeśli ustawimy -lruskips = 100 (dobra wartość stosowana obecnie domyślnie) to próba uzyskania zatrzasku LRU będzie co 100-tny dostęp do bufora, co poprawia współbieżność i wydajność.
Wartość parametru możemy dostosować także online w tym samym miejscu promona co dla -spin (patrz poniższy obrazek). Jeśli mamy dwie pule buforów (-B i -B2) to możemy określić osobno -lruskip i -lruskip2. Mechanizm ten nie jest wykorzystywany w prywatnej puli buforów.